

在推荐系统中常用的推荐算法一般可以分为两类,即 基于内容推荐 以及 协同过滤。另外,还有一类算法专门处理冷启动问题,例如:基于全局最优推荐。
基于内容推荐
基于内容推荐(Content-based Recommendations)非常好理解,简单来说就是根据用户偏好的内容给他推荐其他相似的内容。
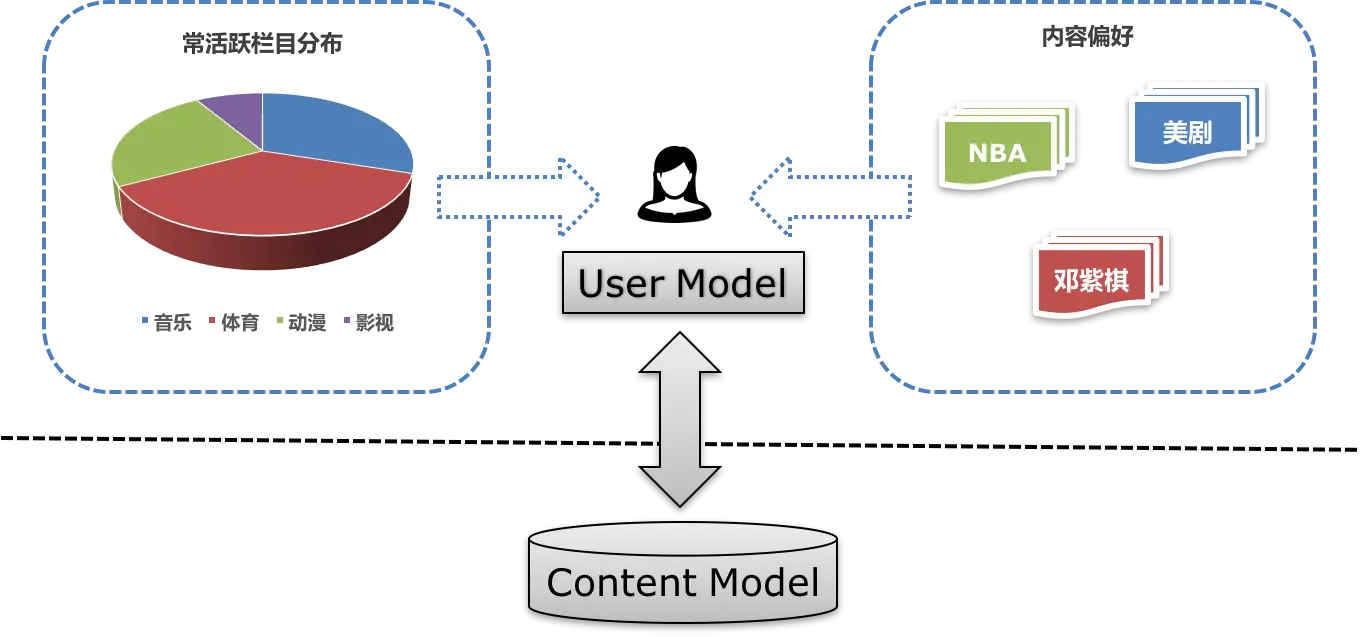
例如:从用户画像我们发现某个用户比较喜欢活跃在“音乐”、“体育”、“动漫”、“影视” 这些栏目,那么我们就会更倾向推荐这些栏目的内容给他,我们还发现他平时偏好的是关于 “NBA”、“美剧”、“邓紫棋” 等方面的内容,那么跟这些相关的内容就会有更高的推荐权重。
评价
基于内容推荐的结果一般具有很强的解释性,因为它推荐的就是强相关的内容,但这种强相关的特点也会导致一个很明显的缺陷,它缺乏惊喜度,因此它很难挖掘用户潜在的兴趣。要解决惊喜度的问题,可以采用另一类算法–协同过滤。
协同过滤
协同过滤(Collaborative Filtering)推荐本质上也是一个找相似的过程,但它认为的相似不是指物品在属性上的相似,而是指在用户行为的层面上这些物品是否有关联,协同过滤一般可以分为 基于用户的协同过滤(User-CF) 和 基于物品的协同过滤(Item-CF)。
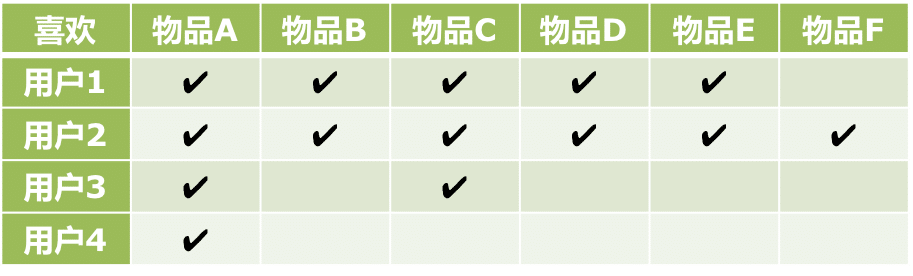
基于用户的协同过滤
解释:因为 用户1 与 用户2 都喜欢物品A、B、C、D、E,所以认为 用户1 和 用户2 是兴趣相似的用户,现在发现 用户2 还喜欢 物品F 所以我们认为 用户1 很可能也对 物品F 感兴趣,所以向 用户1 推荐 物品F。
基于物品的协同过滤
解释:因为喜欢 物品A 的大多数都喜欢 物品C,所以可以认为 物品A 和 物品C 是相似的。用户4 喜欢 物品A 所以向 用户4 推荐 物品C。
评价
协同过滤集合了群体智慧,能满足推荐惊喜度,善于发掘用户潜在的兴趣。训练的用户历史行为数据越多,一般训练出来的模型效果也会越好。协同过滤推荐的解释性一般较弱,推荐结果不如基于内容推荐算法直观,当然这是算法特点导致的,不直观不等于不正确。
冷启动问题
不管是 基于内容推荐 还是 协同过滤推荐,它们都需要依赖用户的历史数据,对于一个新用户而言由于他能提供的行为数据非常少,我们很难通过以上两种方式来找到准确的推荐结果,这时候可以采取一种折衷的方式来解决冷启动的问题,例如:基于全局最优推荐。
基于全局最优推荐
全局最优推荐主要考虑三种维度:popular(流行度)、trending(趋势度)、hot(热门度)。
假设某物品分时段的浏览趋势如下:

相关维度计算如下:

评价
越来越流行的事件它的趋势就越高,而趋势越来越高的事件就会成为一个热点。