

CNN 的核心思想:局部感受野(local field) + 权值共享 + 亚采样 。
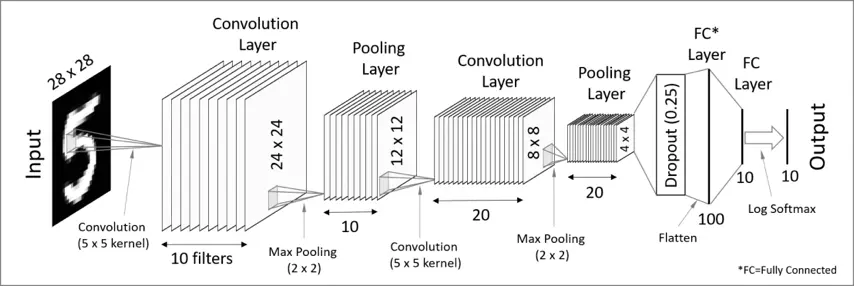
CNN 主要由四类层(layer)组成,即卷积层(Conv)、激活层(Activation)、池化层(Pooling) 以及全连接层(FC/Dense)。
卷积层(Convolution)
传统神经网络采用全连接的方式,往往容易导致需要训练的参数非常庞大,甚至难以训练,卷积神经网络通过卷积层的“局部连接”和“参数共享”的特性大大减少训练参数。
举例:输入 100 x 100, 隐藏层有10个神经元
传统全连接方式(Full Connected)
输入 100 x 100 与每一个神经元连接,需要训练 100 x 100 x 10 = 100000 个参数(不考虑bias)
局部连接(Sparse Connectivity)
假设每个神经元只与局部 10 x 10 个输入连接,那么只需要训练 10 x 10 x 10 = 1000 个参数!!
权值共享(Shared Weights)
如果每个神经元的连接使用相同的权值,那么实际训练参数进一步压缩到 10 x 10 x 1 = 100 个参数!!
卷积层如何生成
卷积核 (或称滤波器,filter/kernel)
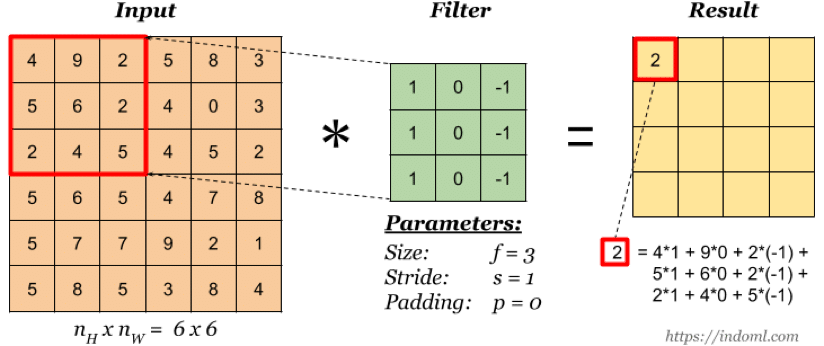
上图是一个尺寸为 3×3 的卷积核, 即每个神经元由输入的 3×3 局部连接所得,卷积核的值通过训练来学习。
卷积核的 stride 值
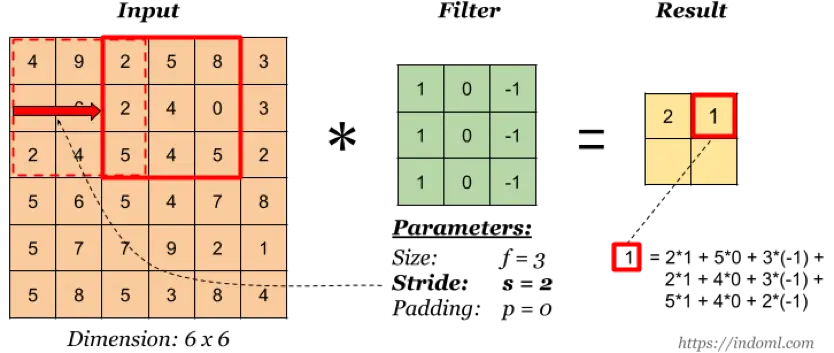
stride 指卷积核的移动步长(这其实就是权值共享的表现),上图 stride=2,卷积核每次移动两个单元。
卷积核的 padding 值
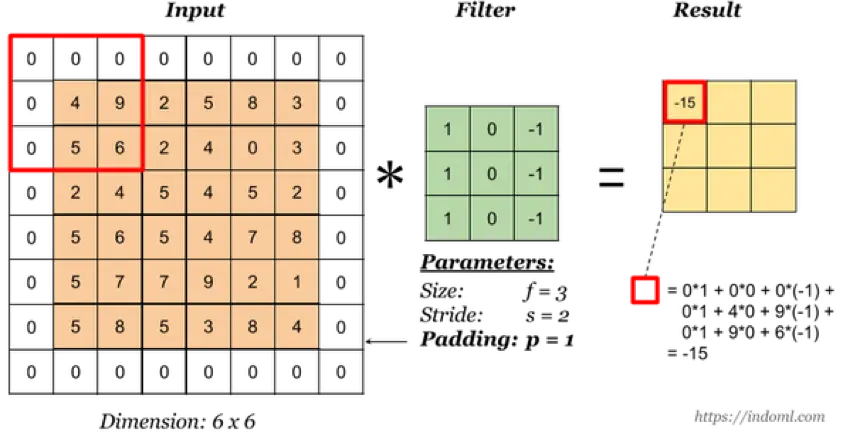
padding 即在输入矩阵的四周添加填充,一方面可以减少原输入的边缘影响,另一方面可以用于维持输入和输出的维度一致(需要 stride 配合)。
padding 的常见术语包括:
(1) valid: 即 no padding
(2) same:通过填充使得输入和输出的维度保持一致
输出维度计算(取下界):
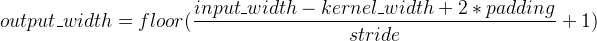
卷积输出-Feature Map(特征图)
实际上卷积核的作用就是对输入层进行特征学习,卷积核可以看成是对输入的一种特征映射,通过这种特征映射,一个卷积核对应生成一个特征图(Feature Map),即上图的 Result。
多通道卷积
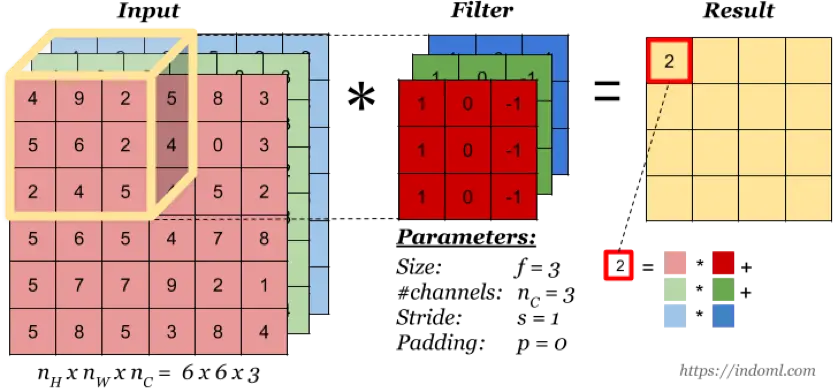
当输入有多个通道(channel)时(例如图片可以有 RGB 三个通道),卷积核需要拥有相同的channel数,每个卷积核 channel 与输入层的对应 channel 进行卷积,将每个 channel 的卷积结果按位相加得到最终的 Feature Map。
多卷积核
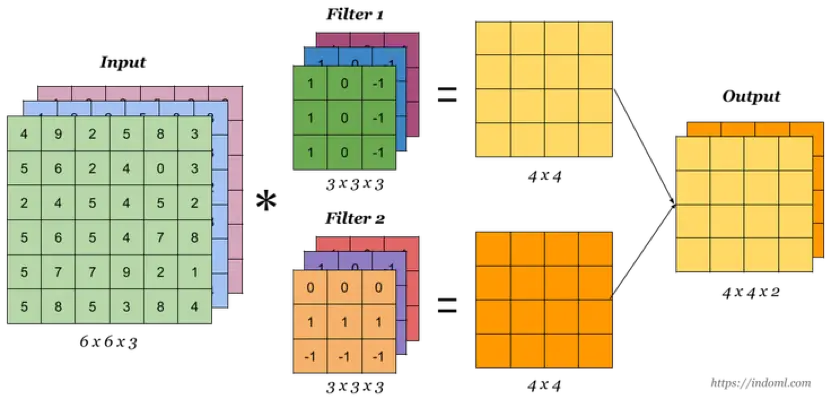
当有多个卷积核时,可以学习到多种不同的特征,对应产生包含多个 channel 的 Feature Map, 例如上图有两个 filter,所以 output 有两个 channel。
为什么不需要全连接而只需要局部连接就会有效果?
对于图像而言,局部区域的像素关联性往往很强,而相距较远的区域关联性往往很弱。同样,对于文本而言,相近的词汇在语义表达上往往有紧密联系而相隔较远的词汇语义关联则相对较低。因此,只需要对局部信息进行特征提取,最后综合起来就能达到全局感知。
激活层(Activation)
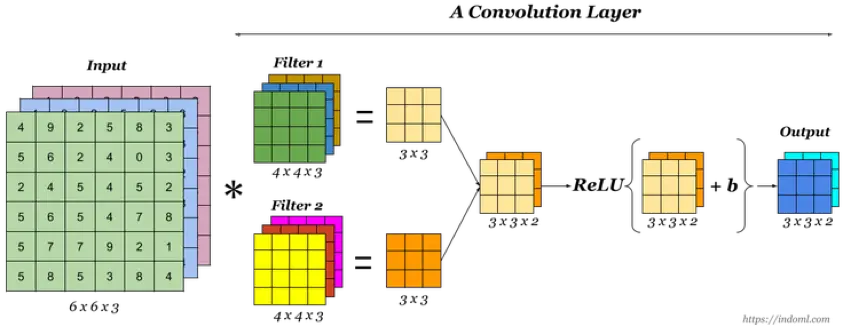
无论是卷积层、池化层还是全连接层它们都是线性的,激活层主要为了引入非线性因素,提升模型的表达能力,一般在卷积或池化之后引入非线性激活(卷积后激活或者池化后激活都可以,顺序不同影响不大)。常用的激活函数有 Relu/PRelu、tanh 等。
池化层(Pooling)
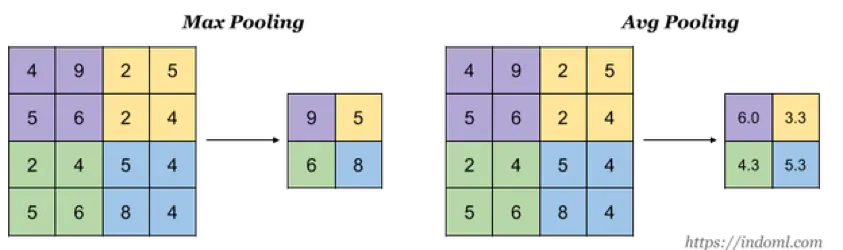
池化层主要对卷积层学习到的特征图进行亚采样(subsampling)处理,意义在于:
1.降低了后续网络层的输入维度,从而减少计算量。
2.增强了 Feature Map 的健壮性(Robust),防止过拟合。
池化层有三个超参数:
1.pool_size 即采样窗口大小
2.stride 即采样窗口的移动步长
3.type 即采样方式,例如:
Max-Pooling(取窗口内的最大值作为输出,常用方式)
Mean-Pooling(取窗口内的所有值的均值作为输出)
全连接层(Full Connection)
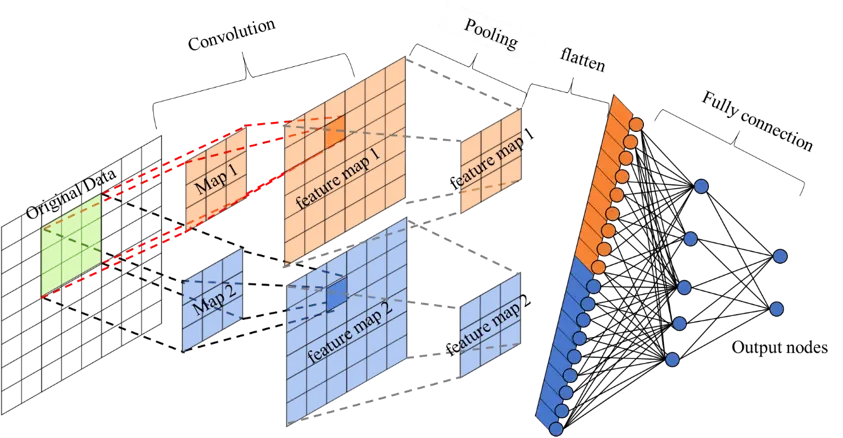
卷积层+激活层+池化层可以看成是CNN的特征学习/特征提取层,而学习到的特征(Feature Map)最终应用于模型任务(分类、回归):
1.先对所有 Feature Map 进行扁平化(flatten, 即 reshape 成 1 x N 向量)
2.再接一个或多个全连接层(和传统前馈神经网络完全一致)进行模型学习
CNN 在 NLP 中的应用
Conv1D
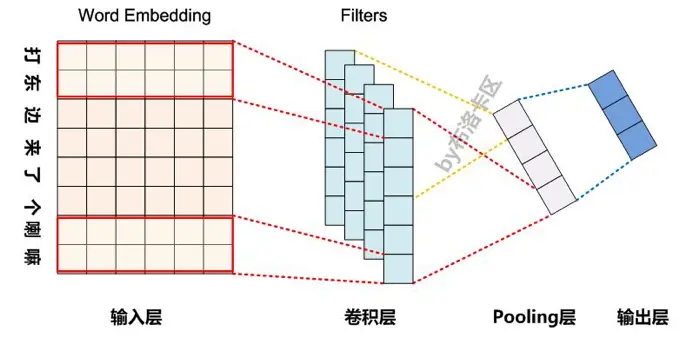
与图像卷积(Conv2D, 即卷积核在 width, height 两个方向上移动)不同,在处理 NLP 问题时一般使用 Conv1D(即只在一个方向上移动),每个词有固定的词向量维度,卷积时对整个词向量做卷积,通过不同的步长即可模拟 N_gram 的效果。
例如:一个 n x d 的 1D 卷积核表示每次对 n 个 d 维词向量进行卷积,每次输出一个神经元(即一个 n gram 特征),卷积一段文本后得到一个 Feature Map。
Max-Pooling1D
同样,在 NLP 问题中 Pooling 通常也是 1D 的:
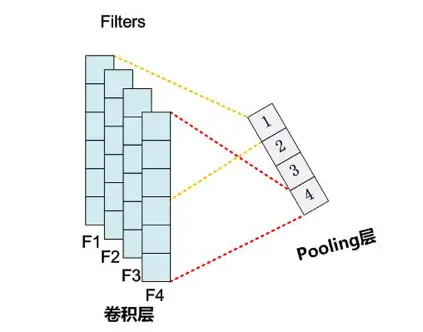
Max-Pooling1D 实际上就是提取每个 Feature Map 的最大特征值,然后 concat 成一个新的特征。
K-Max Pooling
虽然对于一般的分类问题 Max Pooling 已经足够了,但由于 Max Pooling 会破坏特征的位置信息,并且无法表示多个强特征(因为每次只取一个 Max),对于一些对特征位置以及强特征次数敏感的分类问题(例如情感分析),更常用的是 K-Max Pooling:
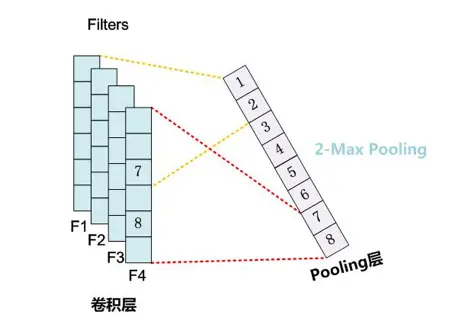
相当于每次取 Feature Map 的 top k 个特征值,一方面保留了关键特征的局部顺序,另一方面增加了对多个强特征的感知能力。
CNN 与 RNN/LSTM 在文本分类任务中的比较
1.RNN/LSTM 一般更适合短文本分类任务;
2.超长文本/文档分类任务上通常 CNN 比 RNN 更适合;
3.情感分析任务更适合用 LSTM,因为 CNN 对语序破坏太大,而情感分析任务往往对语序特别敏感。例如:“今天下雨心情很不好” vs “今天不下雨心情很好”。同样的词汇,不同语序导致情感色彩完全不同。