

之前的文章中介绍过提取文本标签特征(关键词)的几种算法TF-IDF、TextRank、TWE, 提取到标签特征后,我们可以进一步推断文本的内容分类。本文主要介绍通过词向量模型进行内容分类的一般思路。
提取文本标签特征
假设有以下一段文本:
2016/17赛季欧冠决赛在威尔士卡迪夫千年球场打响,最终尤文图斯以1-4不敌皇家马德里,遗憾错失冠军。赛后,尤文门将布冯表示对结果非常失望,因为尤文已经做了所有能做的事情。
通过关键词提取算法我们提取到以下标签:
#欧冠、#决赛、#尤文图斯、#皇家马德里、#布冯、#门将、#球场、#冠军
假设我们有一个关于体育的分类体系:
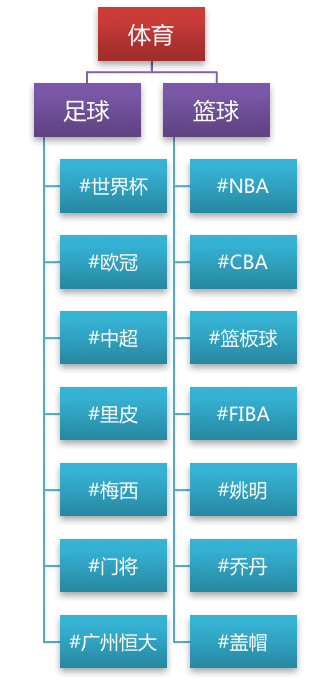
图:分类体系
- 一级分类:体育
- 二级分类:篮球(关联标签:NBA,CBA,篮球,篮板球,助攻,盖帽,FIBA,姚明,乔丹,三双…)
- 二级分类:足球(关联标签:世界杯,亚冠,欧冠,中超,足球,英超,西甲,梅西,里皮,马拉多纳,门将,广州恒大,曼联…)
分类推断
通过词向量模型(Word2Vec)我们可以计算两个词之间的相似度(余弦距离):
Similarity(tagA, tagB) = cos(tagA_Vec, tagB_Vec)
因此,计算文本与分类的相似度实际上就是计算文本的标签与各个分类的关联标签的相似度。
我们发现上面这段文本与足球的相似度大于与篮球的相似度:
Dist(doc_tags, soccer_tags) > Dist(doc_tags, basketball_tags)
所以推断它是关于足球的内容,再进一步把它归类到体育这个一级分类。