

NameNode是HDFS(hadoop分布式文件系统)的核心组件,在hadoop 1.x中NameNode存在SPOF(单点故障)问题,NameNode存储了HDFS的元数据信息,一旦NameNode宕机那么整个HDFS就无法访问,依赖HDFS的服务也会被波及(HBase、Hive…)同样无法访问,整个集群陷入瘫痪。NameNode的单点故障问题也使得Hadoop在1.x时代一直都只能用作离线存储和离线计算,无法满足对高可用要求很高的应用场景。Hadoop2.x针对NameNode的SPOF问题提出了高可用架构方案(HA),目前已经能在生产环境下应用。本文主要介绍该高可用架构的主备切换机制。
一、NameNode高可用架构
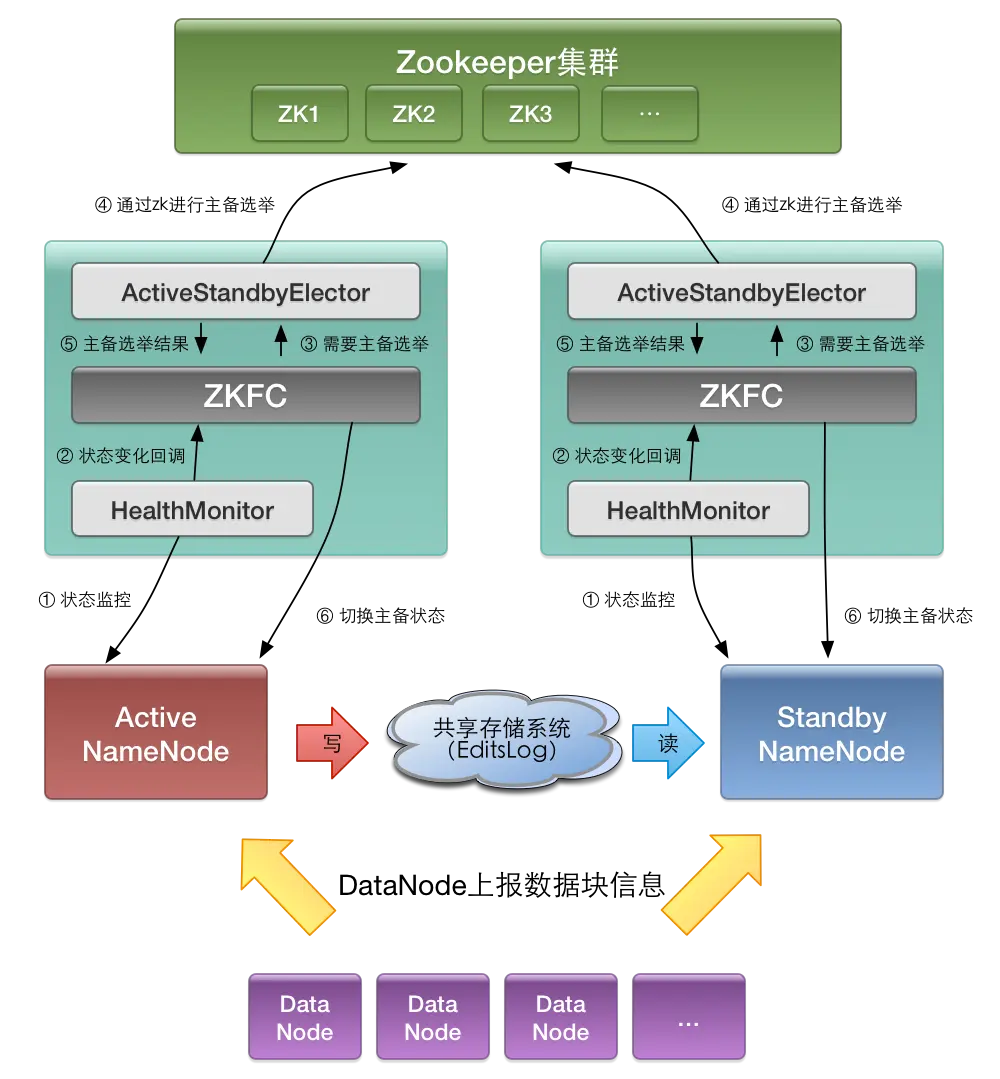
二、组件概述
Active NameNode 与 Standby NameNode
在NameNode的HA方案中有两个不同状态的NameNode,分别为活跃态(Active)和后备态(Standby),其中只有Active NameNode能对外提供服务,Standby NameNode会根据Active NameNode的状态变化,在必要时可切换成Active.
ZKFC
ZKFC即ZKFailoverController,是基于Zookeeper的故障转移控制器,它负责控制NameNode的主备切换,ZKFC会监测NameNode的健康状态,当发现Active NameNode出现异常时会通过Zookeeper进行一次新的选举,完成Active和Standby状态的切换
HealthMonitor
周期性调用NameNode的HAServiceProtocol RPC接口(monitorHealth 和 getServiceStatus),监控NameNode的健康状态并向ZKFC反馈
ActiveStandbyElector
接收ZKFC的选举请求,通过Zookeeper自动完成主备选举,选举完成后回调ZKFC的主备切换方法对NameNode进行Active和Standby状态的切换.
DataNode
NameNode包含了HDFS的元数据信息和数据块信息(blockmap),其中数据块信息通过DataNode主动向Active NameNode和Standby NameNode上报
共享存储系统
共享存储系统负责存储HDFS的元数据(EditsLog),Active NameNode(写入)和 Standby NameNode(读取)通过共享存储系统实现元数据同步,在主备切换过程中,新的Active NameNode必须确保元数据同步完成才能对外提供服务
三、主备切换流程
① 监控状态
HealthMonitor调用NameNode的RPC方法monitorHealth监控NameNode的健康状态,包括
- INITIALIZING:HealthMonitor正在启动中,未开始监控
- HEALTH_MONITOR_FAILED:HealthMonitor运行出错,触发ZKFC的fatalError,ZKFC进程退出
- SERVICE_NOT_RESPONDING:调用NameNode的monitorHealth方法无响应
- SERVICE_UNHEALTHY:NameNode正在运行,但NameNode健康检查失败,抛出HealthCheckFailedException异常
- SERVICE_HEALTHY:NameNode正常运行
HealthMonitor调用NameNode的RPC方法getServiceStatus监控NameNode的角色状态,包括
- INITIALIZING:NameNode正在启动中
- ACTIVE:NameNode当前为Active NameNode
- STANDBY:NameNode当前为Standby NameNode
- STOPPING:NameNode已经停止
② 状态变化回调
当NameNode的健康状态或角色状态发生变化时,HealthMonitor会回调ZKFC注册的回调方法,ZKFC根据状态的变化决定是否需要进行选举
③ 需要主备选举
NameNode的健康状态(state)变化在主备选举中起核心作用,ZKFC在不同状态下的决策:
- SERVICE_HEALTHY:NameNode有资格进行主备选举,调用ActiveStandbyElector的joinElection发起一次主备选举
- SERVICE_NOT_RESPONDING 或 SERVICE_UNHEALTHY:NameNode不适合成为Active NameNode,调用quitElection(true)从Zookeeper上删除已经建立的临时节点退出主备选举,并进行隔离
- INITIALIZING:HealthMonitor未开始监控,调用quitElection(false)从Zookeeper上删除已经建立的临时节点退出主备选举,不需要隔离
NameNode的角色状态(status)变化在主备选举中起辅佐作用,ZKFC会比较NameNode的最新角色和自己期望的角色是否一致,如果不一致则调用quitElection退出主备选举
④ 通过zk进行主备选举
ZKFC通过ActiveStandbyElector的joinElection发起NameNode的主备选举,这个过程利用了Zookeeper的写一致性和临时节点机制:
- 当发起一次主备选举时,Zookeeper会尝试创建临时节点ActiveStandbyElectorLock,如果创建成功则表示该NameNode竞选Active成功,否则视为竞选失败,最后会通知ZKFC
- 不管竞选是否成功(有且只有一个NameNode竞选成功),所有ActiveStandbyElector都会向Zookeeper注册一个watcher用于监听临时节点ActiveStandbyElectorLock的NodeDelete事件
- 当调用quitElection退出主备选举或Active NameNode由于宕机使临时节点ActiveStandbyElectorLock被Zookeeper自动删除时就会触发NodeDeleted事件,Standby NameNode会再次尝试创建ActiveStandbyElectorLock,一旦创建成功则该Standby NameNode竞选Active成功,最后通知ZKFC
防止脑裂:
在分布式系统中脑裂又称为双主现象,由于Zookeeper的“假死”可能会导致出现两个NameNode同时为Active状态,此时两个NameNode都可以对外提供服务,无法保证数据一致性。ActiveStandbyElector通过隔离(Fencing)机制防止脑裂现象。
当某个NameNode竞选成功,成功创建ActiveStandbyElectorLock临时节点后会创建另一个名为ActiveBreadCrumb的持久节点,该节点保存了NameNode的地址信息,正常情况下删除ActiveStandbyElectorLock节点时会主动删除ActiveBreadCrumb,但如果由于异常情况导致Zookeeper Session关闭,此时临时节点ActiveStandbyElectorLock会被删除,但持久节点ActiveBreadCrumb并不会删除,当有新的NameNode竞选成功后它会发现已经存在一个旧的NameNode遗留下来的ActiveBreadCrumb节点,此时会通知ZKFC
⑤ 通知ZKFC主备选举结果
主备选举结束后ZKFC会收到ActiveStandbyElector反馈的选举结果,包括:竞选Active成功、竞选Active失败、发现旧的Active NameNode遗留的ActiveBreadCrumb等
⑥ 切换主备状态
收到主备选举结果后ZKFC会根据选举结果进行NameNode的Active和Standby状态变更:
- 竞选Active成功:回调NameNode的 transitionToActive 方法使其成为Active状态
- 竞选Active失败:回调NameNode的 transitionToStandby 方法使其成为Standby状态
- 发现遗留ActiveBreadCrumb:调用 fenceOldActive 方法隔离旧的Active NameNode(首先尝试把它设为Standby,不行就ssh到目标机器上杀死进程或执行自定义的shell进行隔离),只有成功隔离后新的NameNode才会被设为Active状态并对外提供服务