

NameNode是HDFS(hadoop分布式文件系统)的核心组件,在hadoop 1.x中NameNode存在SPOF(单点故障)问题,NameNode存储了HDFS的元数据信息,一旦NameNode宕机那么整个HDFS就无法访问,依赖HDFS的服务也会被波及(HBase、Hive…)同样无法访问,整个集群陷入瘫痪。NameNode的单点故障问题也使得Hadoop在1.x时代一直都只能用作离线存储和离线计算,无法满足对高可用要求很高的应用场景。Hadoop2.x针对NameNode的SPOF问题提出了高可用架构方案(HA),目前已经能在生产环境下应用。本文主要介绍该高可用架构的主备切换机制。
一、NameNode高可用架构
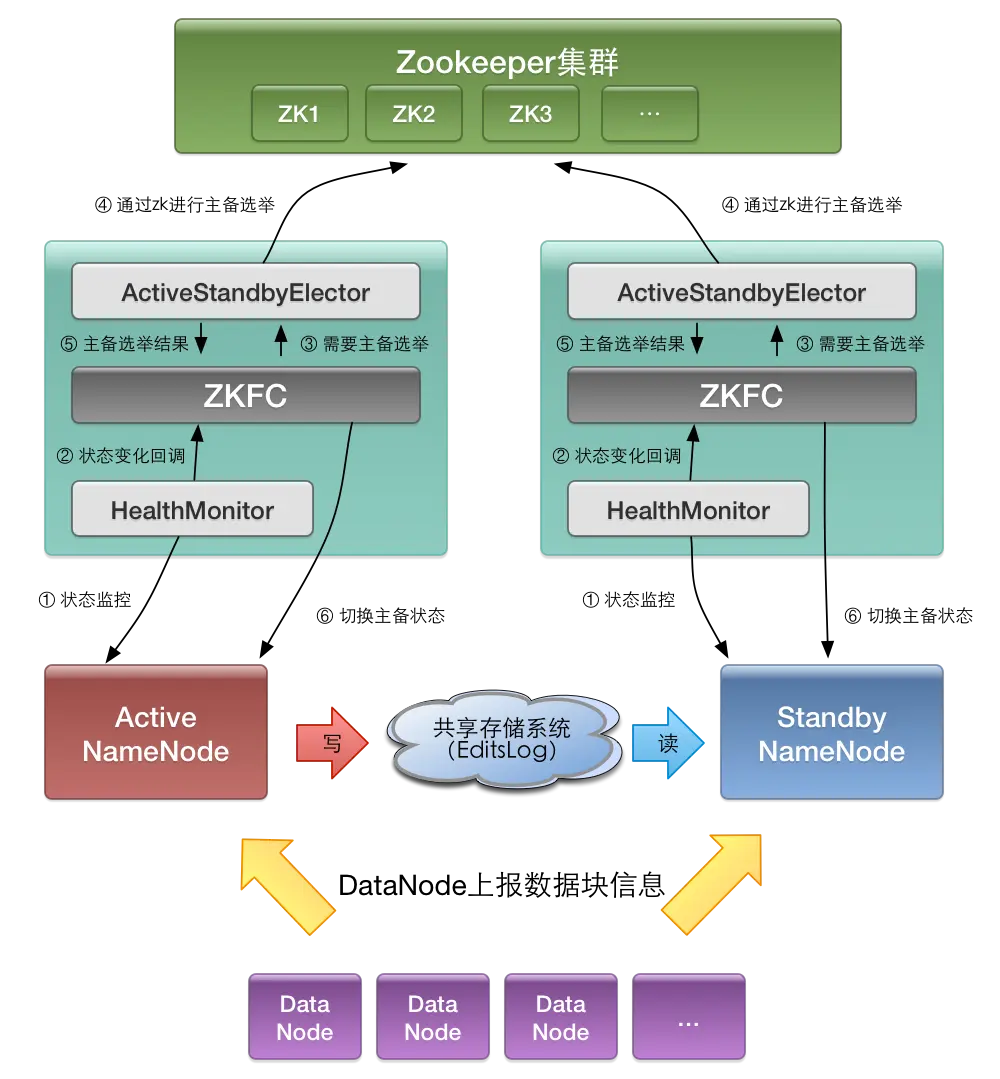
Hadoop NameNode高可用架构
二、组件概述
Active NameNode 与 Standby NameNode
在NameNode的HA方案中有两个不同状态的NameNode,分别为活跃态(Active)和后备态(Standby),其中只有Active NameNode能对外提供服务,Standby NameNode会根据Active NameNode的状态变化,在必要时可切换成Active.
ZKFC
ZKFC即ZKFailoverController,是基于Zookeeper的故障转移控制器,它负责控制NameNode的主备切换,ZKFC会监测NameNode的健康状态,当发现Active NameNode出现异常时会通过Zookeeper进行一次新的选举,完成Active和Standby状态的切换