

spark 可以通过 BlockMatrix 进行矩阵相乘,但其在大规模稀疏矩阵场景有非常严重的性能问题,本文通过基于 RDD 和 DataFrame 两种方式实现基于 spark 的大规模稀疏矩阵乘法运算。
一、矩阵乘法运算

二、通过 BlockMatrix 进行矩阵相乘
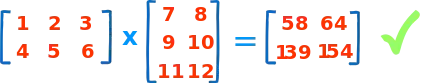
from pyspark.mllib.linalg.distributed import *
from pyspark.sql import SparkSession
ss = SparkSession.builder.appName("test") \
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.getOrCreate()
sc = ss.sparkContext
sc.setLogLevel("WARN")
M_rdd = sc.parallelize([(0,0, 1), (0,1, 2), (0,2, 3), (1,0, 4), (1,1, 5), (1,2, 6)])
N_rdd = sc.parallelize([(0,0, 7), (0,1, 8), (1,0, 9), (1,1, 10), (2,0, 11), (2,1, 12)])
M = CoordinateMatrix(M_rdd).toBlockMatrix()
N = CoordinateMatrix(N_rdd).toBlockMatrix()
M.multiply(N).toCoordinateMatrix().entries.collect()
######## 输出 #############
# [MatrixEntry(0, 0, 58.0),
# MatrixEntry(1, 0, 139.0),
# MatrixEntry(0, 1, 64.0),
# MatrixEntry(1, 1, 154.0)]
三、BlockMatrix 的性能问题
在 spark 的官方文档中关于 multiply 这个方法的描述如下
Left multiplies this BlockMatrix by other, another BlockMatrix. The colsPerBlock of this matrix must equal the rowsPerBlock of other. If other contains any SparseMatrix blocks, they will have to be converted to DenseMatrix blocks. The output BlockMatrix will only consist of DenseMatrix blocks. This may cause some performance issues until support for multiplying two sparse matrices is added.
也就是说,BlockMatrix 在进行矩阵乘法时会先把稀疏矩阵转换成稠密矩阵!!对于一个 10000 x 10000 的稀疏矩阵,实际存储的可能只有几万个非零元素,而转换成稠密矩阵后,你需要对所有 10000 x 10000 = 1亿 个元素提供存储空间!!而实际场景面对的稀疏矩阵的维度远远大于 10000,所以 BlockMatrix 无法适用于大规模稀疏矩阵运算。
四、矩阵乘法公式


从矩阵乘法公式可知,矩阵相乘主要有以下环节:
1.左矩阵的列号(j)与右矩阵的行号(j)相同的元素进行两两相乘得到 MN_ik。
2.对所有具有相同下标(ik)的 MN_ik 进行相加,即得到 P_ik。