

HDFS(hadoop分布式文件系统)是Hadoop的核心组成部分,HDFS采用master/slave架构,一个HDFS集群由一个NameNode(不考虑HA/Federation)和多个DataNode组成
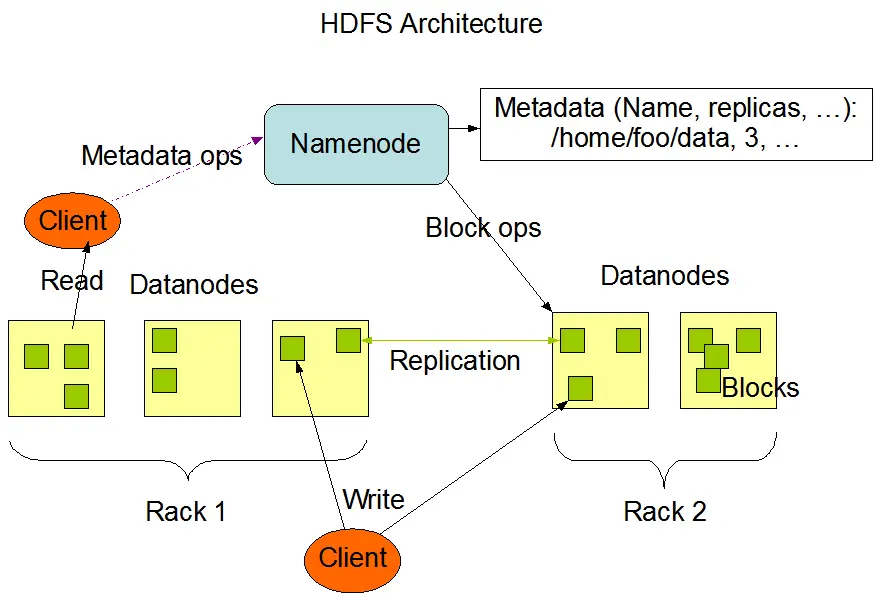
HDFS架构图(via Apache Hadoop)
一、NameNode
- NameNode是HDFS的中心,也称作Master
- NameNode只保存HDFS的元数据,负责管理HDFS的命名空间(namespace)和控制文件的访问操作
- NameNode不保存任何实际的数据或数据集,真正的数据由DataNode负责存储
- NameNode拥有HDFS内所有文件的数据块(blocks)列表及其位置,因而NameNode能通过这些数据块信息来重构对应的文件
- NameNode是HDFS的核心,一旦NameNode挂了,整个集群将无法访问
- NameNode具有单点故障问题(Hadoop2之后可以通过High Available方案解决)
- NameNode需要配置相对较多的内存(相比DataNode而言),因为NameNode会把HDFS的命名空间和文件数据块映射(Blockmap)保存在内存中,这也意味着集群的横向扩展受到NameNode的限制,因为集群增长到一定的规模后NameNode需要的内存也会更大,另外由于所有的元数据操作都需要通过NameNode进行,这意味着集群的性能受到NameNode的限制(Hadoop2之后可以通过Federation方案解决)
- NameNode有两个核心的数据结构,FsImage和EditsLog,FsImage是HDFS命名空间、文件数据块映射、文件属性等信息的镜像,EditsLog相当于一个日志文件,它记录了对HDFS元数据进行修改的所有事务操作,当NameNode启动时会首先合并FsImage和EditsLog,得到HDFS的最新状态然后写入FsImage镜像文件中,并使用一个新的EditsLog文件进行记录
SecondaryNameNode
“SecondaryNamenode”这个名字具有误导性,它不能和DataNode交互,更不能替代NameNode,相反它是用来弥补NameNode的一些缺点,由于NameNode启动时会合并FsImage和EditsLog,但随着集群的运行时间变长,EditsLog会变得非常庞大,这意味着下一次启动需要花很长的时间来进行合并操作.
SecondaryNameNode负责解决以上的问题
阅读全文