

通过结合多个模型来完成学习任务,生成更强大的模型,相比单一模型,集成学习往往具有更好的泛化能力。根据结合的模型的类型是否相同(是否由相同算法生成),可以分为同质和异质。
根据结合方式的不同,集成学习可以分为两大类
模型之间不存在强依赖关系,可以并行训练,例如:Bagging、Random Forest
模型之间存在强依赖关系,必须串行化训练,例如:AdaBoost
Bagging(并行集成)

- 为了保证每个基模型的差异(集成学习的关键,样本差异可以使得模型关注不同角度),每个模型的训练集通过自助采样(.632 Bootstrap 采样)的方式生成 。
自助采样:等概率 、 有放回地从训练集中抽取 n 个样本作为训练集(相同样本可能出现多次),其余没有被抽到的样本作为测试集,原始训练集的 63.2% 的样本会出现在训练集中。
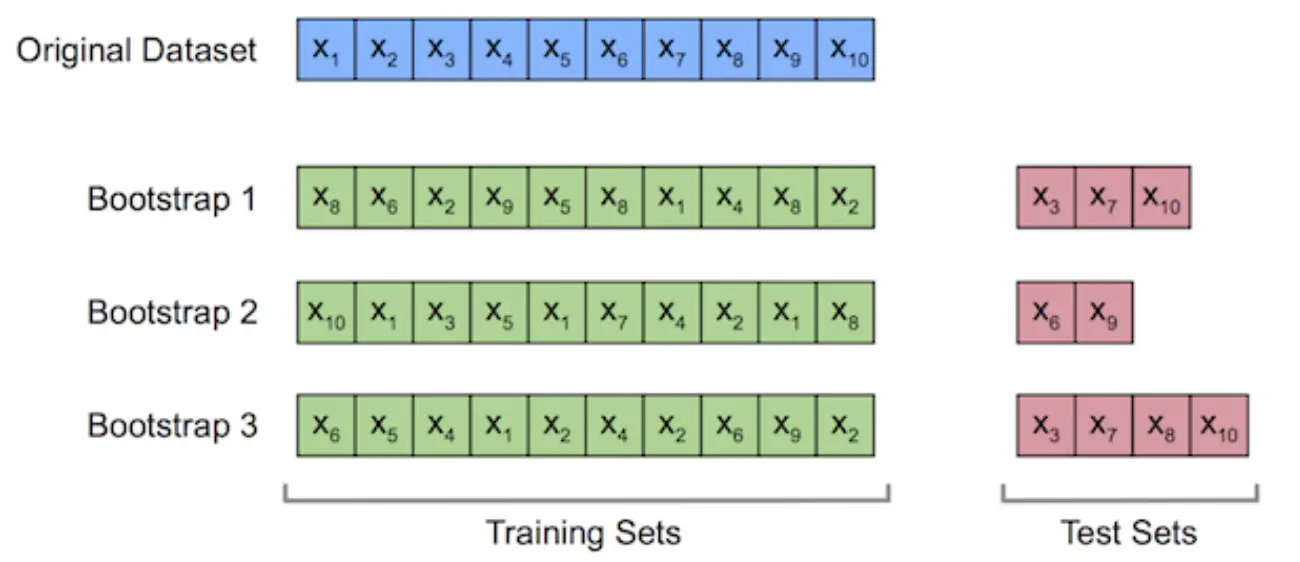
- 输出预测方式:投票法(分类),平均法(回归)
- 优点:
由于多个模型可以并行训练,所以训练比较高效 ;
结合多个模型的预测能力,能有效提升泛化能力(即更低的方差 low variance)
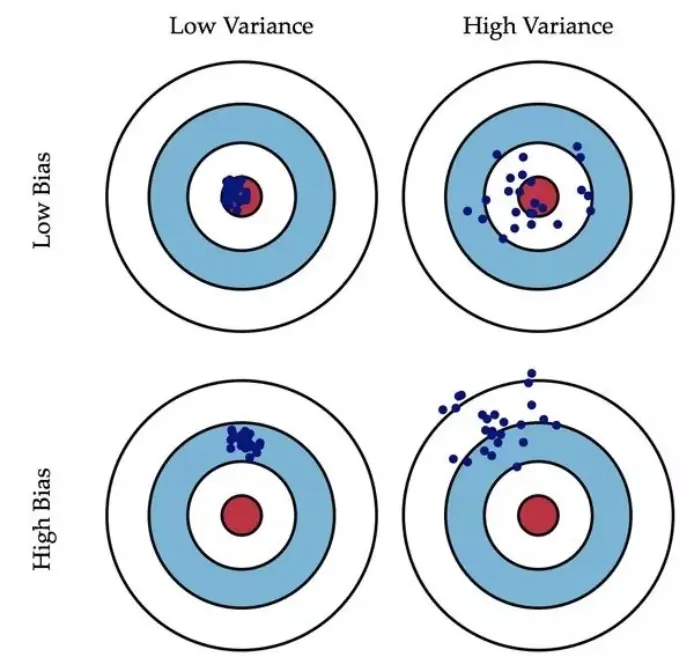
Bias:训练样本准确率(更复杂的模型)
Variance:测试样本的准确率(泛化能力,更简单的模型)
Boosting(串行集成)
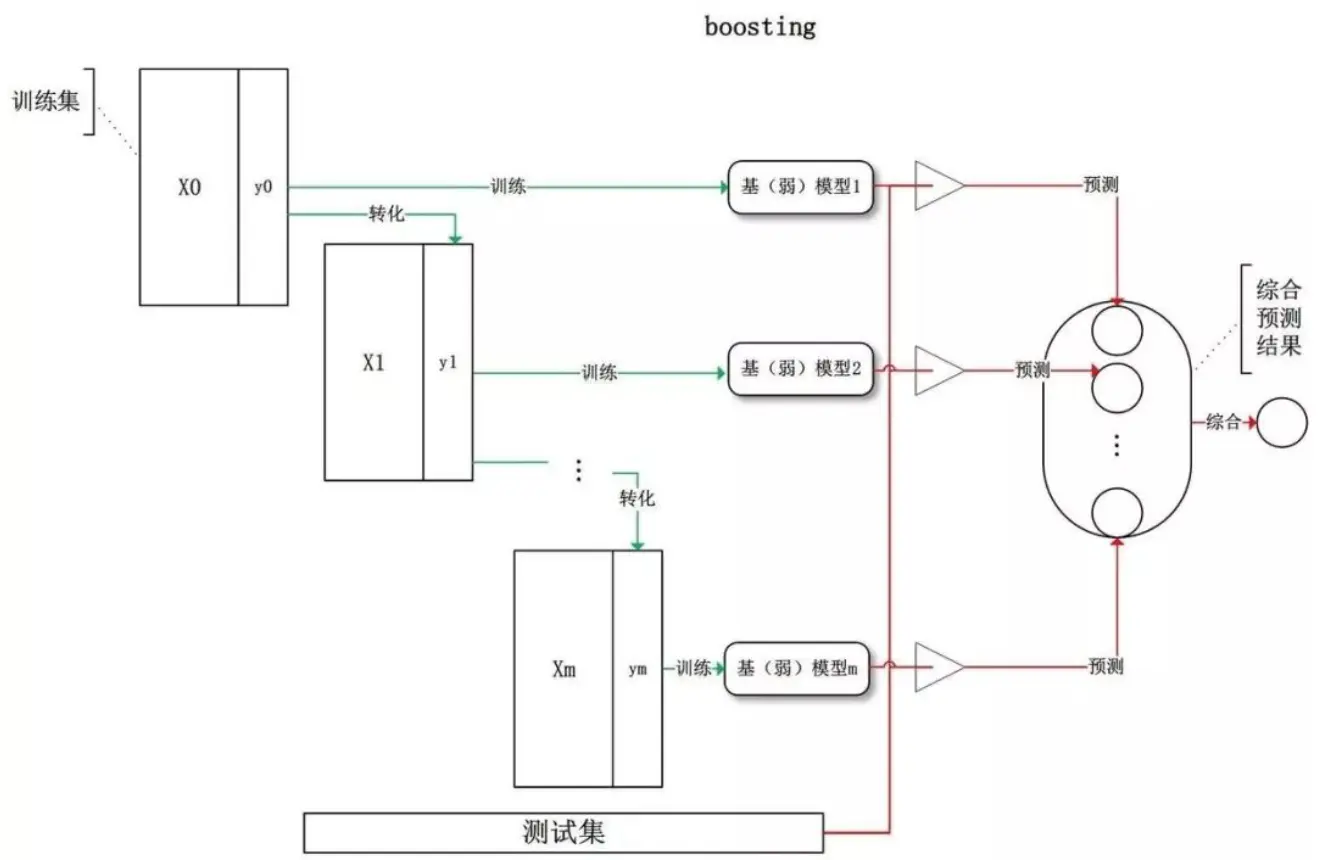
- 从初始训练集学习一个基模型。
- 根据上一个基模型的表现调整训练样本的分布(增加误分样本的权重,降低正确分类样本的权重)。
- 基于新的样本分布初始化新的训练集(误分样本更被重视)训练新的基模型。
- 重复以上步骤直到生成 T 个模型,通过加权线性结合所有基模型并进行预测。
- 偏向降低模型偏差(bias)