

SVM是一种二元分类模型(当然它也可以处理回归问题),它通过训练样本寻找分隔两类样本的最优决策边界(超平面),使得两类样本距离决策边界的距离最远(例如H3)。其中距离决策边界最近的样本称为支持向量(即深色的苹果和香蕉),支持向量所在的与决策平面平行的平面称为支撑平面(虚线),支撑平面与决策平面的距离称为间隔(margin),SVM寻找最优决策边界实际上就是要最大化(最大可信度)两个支撑平面的间隔(决策平面位于两者的中间)。
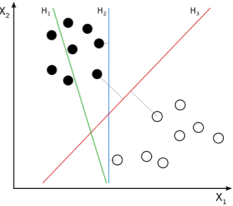
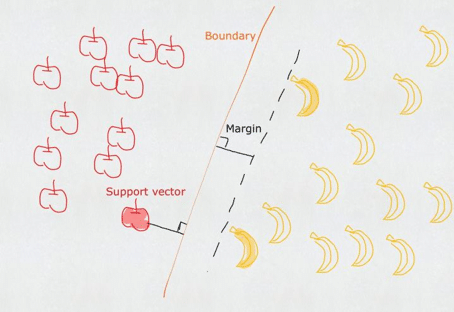
SVM 模型根据数据集的差异可以分为三种类型:
- 线性可分 => 硬间隔最大化 => 线性可分SVM
- 线性不可分(有噪音)=> 软间隔最大化 => 线性 SVM(引入松弛变量和惩罚函数)
- 非线性可分 => 软间隔最大化 + 核函数 => 非线性 SVM
一、线性可分(硬间隔最大化)
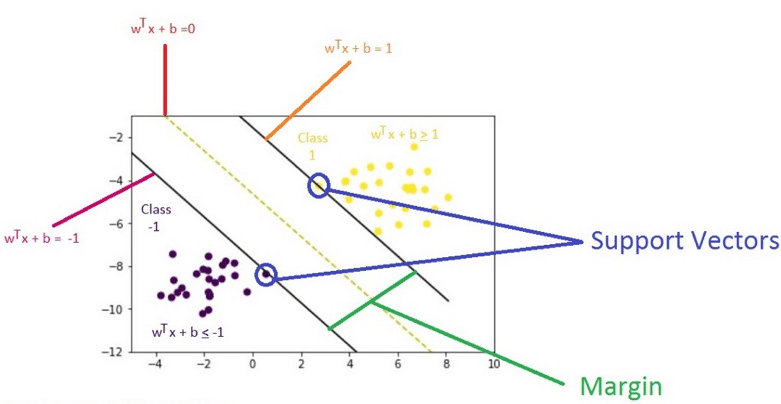
假设决策超平面为: W·X + b = 0
正类支撑平面为: W·X + b = γ
由对称关系可知负类支撑平面为: W·X + b = -γ
由于平面等比例缩放依然属于同一平面, 即 5W·X + 5b = 5 与 W·X + b = 1 是同一个平面
所以前面的假设可以更简洁地表示为(按γ等比例缩放):
决策平面: W·X + b =0
正类的支撑平面: W·X + b = 1
负类的支撑平面: W·X + b = -1
要求满足以下规则:

计算两个支撑平面的距离(margin)
由两平面距离公式可知,平面 W·X + b + 1 = 0 与平面 W·X + b -1 = 0的距离为:
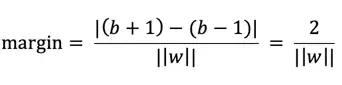
所以要最大化margin相当于要最小化 ||w|| 即等价于:
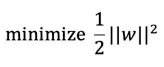
最终的优化问题(目标函数)变成:

二、线性不可分(软间隔最大化)
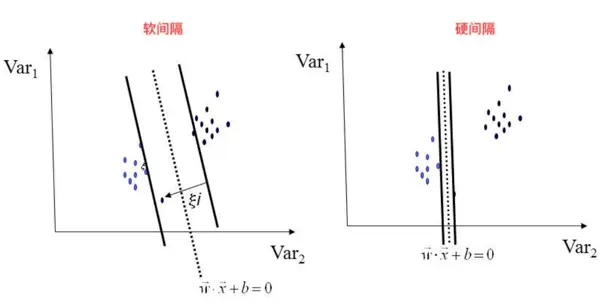
当训练数据含有噪音数据时,如果进行硬间隔最大化可能会导致间隔过小甚至无法求解。
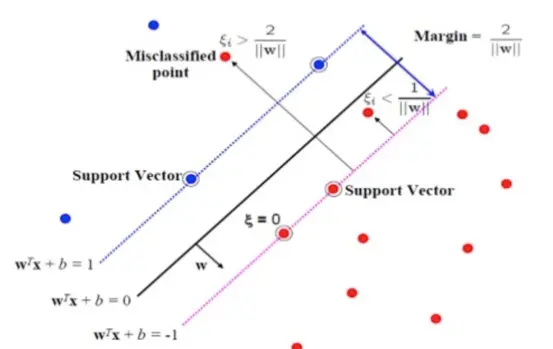
此时我们引入松弛变量(Slack Variable)ξ (epsilon ξ≥0) ,将原来的不等式约束变为:

松弛变量相当于为支撑平面提供了一个容错的区间,允许噪音数据存在(误分类样本),当松弛变量越大那么容错范围越大,反之,当ξ=0,等价于硬间隔最大化。当然我们不能无限制地容错,为了调和“间隔最大化”和“区分最大化”我们引入惩罚参数C,目标函数变成:
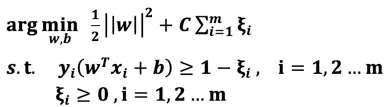
说明:相当于将“经验风险最小化问题”转变为引入了置信风险的“结构风险最小化问题”
说明:ξ_i≥0 与 hinge loss:max(0,1-y_i (w^T x_i+b)) 实际上是等价的。
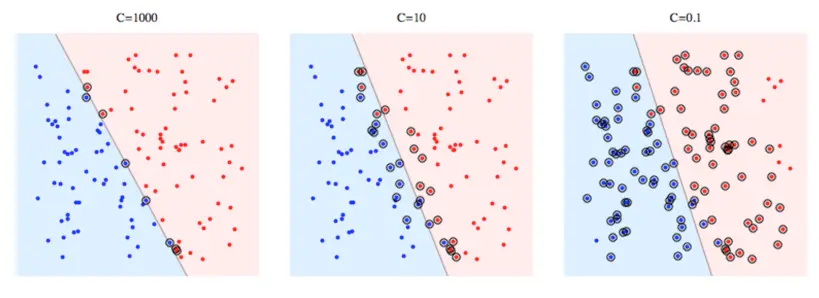
当C 越大,模型对误分类的惩罚越大,相当于分类更精确,但同时会牺牲间隔距离,可能导致过拟合。
当C 越小,模型对误分类的惩罚越少,相当于更倾向于间隔距离最大化以提升泛化能力,但同时牺牲了分割性,可能导致欠拟合。
构造广义拉格朗日函数

由于第一步针对α和β的最大化含有约束条件,为了更方便求解问题,我们将求解原问题转化为求解其对偶问题(由于满足KKT条件所以对偶问题的解与原问题的解相等),即拉格朗日极大极小值问题:
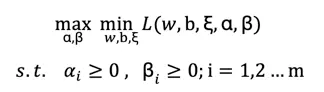
分别对w、b、ξ 求偏导等于0得:
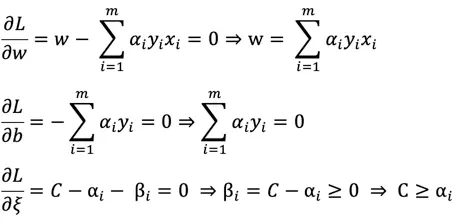
代入L消除w、b、ξ、β 得问题的最终表达式
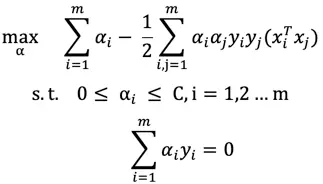
通过SMO算法求解α的最优解(将大优化问题,分解为多个小优化问题即只有两个变量的二次规划子问题)
求得最优 α* 后可以求得对应的w* 、b*:
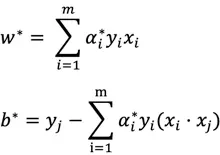
所以可知决策函数为:
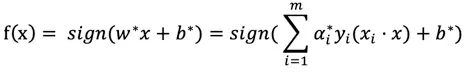
备注:因为α_i*g(w,b,ξ)=0 所以只有当g = 0时(样本为支持向量),α>0,其余情况α=0,因此决策函数只与支持向量有关。
三、非线性可分
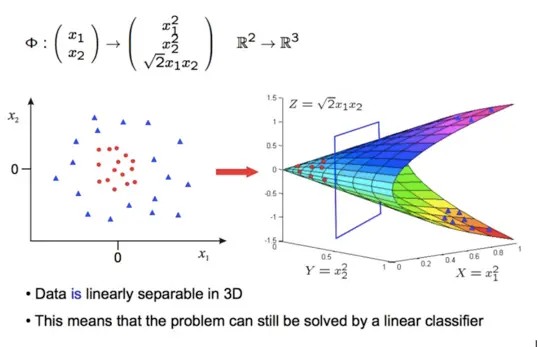
有时候数据集可能是非线性可分的,此时需要将原始特征映射φ到更高维的特征空间,使得样本在高维特征空间内线性可分,然后通过学习线性分类器的方法找到高维空间下的分类超平面。
然而直接将原始特征映射到高维特征再进行计算并不容易,当原始特征非常多时,映射后的维数也会非常高,此时计算量会非常大,甚至出现“维数灾难”,为了避免直接在高维空间进行计算,我们引入核函数解决。
K(x,y)=<φ(x),φ(y)>
核函数的作用:在低维空间的计算结果与映射到高维空间后的表现等效,核函数可以理解为对高维空间的一种隐式映射。
例子:x = (x1, x2, x3); y = (y1, y2, y3).
定义映射 φ(x) = (x1x1, x1x2, x1x3, x2x1, x2x2, x2x3, x3x1, x3x2, x3x3), 将3维映射到9维
定义核函数K(x, y ) = (<x, y>)².
假设 x = (1, 2, 3); y = (4, 5, 6). 那么
φ(x) = (1, 2, 3, 2, 4, 6, 3, 6, 9)
φ(y) = (16, 20, 24, 20, 25, 30, 24, 30, 36)
<φ(x), φ(y)> = 16 + 40 + 72 + 40 + 100+ 180 + 72 + 180 + 324 = 1024
使用核函数快速计算:
K(x, y) = (4+10+8)²= 32² = 1024
引入核函数后的目标函数变为:
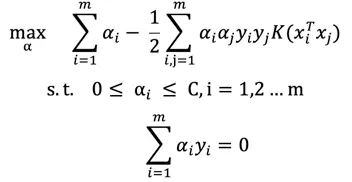
决策函数:

四、常用核函数
线性核
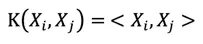
径向基函数核(RBF,SVM最常用的核函数)
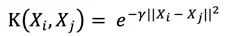
备注:γ决定RBF核的非线性程度,γ越大,分类边界的非线性表达能力越突出,但可能导致过拟合,相反,γ越小,分类边界越倾向于线性边界,即更接近低维空间。这就是为什么sklearn的SVM中,gamma默认是1/n_features,因为特征越多,越能线性可分,所以核函数的非线性能力相应可以降低。
多项式核(Polynomial kernel,多用于NLP问题)

五、SVM调参方式
以RBF-SVM为例,主要涉及惩罚参数C和核参数γ。常用的调参方式是基于交叉验证的网格搜索(GridSearchCV),即尝试不同的(C,γ)组合,选择交叉验证精度最高的组合作为最优参数。
六、多分类(one vs one):
将k个类进行两两配对,产生k(k-1)/2个分类器(只需在对应两类的样本中进行训练),所有分类器对新样本进行预测,得票最多的类别为预测分类结果。
七、SVM优点
- 泛化能力强(优化目标是结构风险最小化,即具有正则项,能有效防止过拟合)
- 通过核函数对高维空间的隐式映射,能有效解决非线性问题。
八、SVM缺点
- 对于大规模数据训练,由于计算量较大,训练效率较低。(究其根本,核化的SVM本身的时间复杂度 O(nm^2) 就是二次时间,m是样本数,n是特征数。当数据量较大的时候,还面临空间复杂度的问题,cache的储存可能不够)
- 模型解释性较弱,无法给出概率结果。
- 本身是一个二分类模型,对于多分类问题比较乏力,需要采用one vs one, one vs all。
- 对于非线性问题,核函数的选择以及调参比较麻烦。
九、应用场景
小样本、非线性、高维
十、SVM与逻辑回归的比较
- 逻辑回归收敛于任何可以将样本分隔的决策边界(虽然是最大似然估计,但本质关心的只是会不会发生),而SVM则选择间隔最大化的分界作为决策边界,这通常意味着SVM具有更好的泛化能力
- SVM可以通过引入非线性核解决非线性问题
- SVM(尤其是核化的SVM)相比逻辑回归需要更大的计算成本
- SVM 无法直接给出概率解释(需要通过代价高昂的五折交叉验证方法计算概率),逻辑回归可以直接给出概率解释。
十一、算法选择
- 特征数很大(特征≥10000,或接近样本数):使用逻辑回归或者线性核SVM
- 特征数少,样本数适中(特征≤1000,样本≤10000):使用RBF-SVM
- 特征数少,但样本数很大:增加特征,然后使用逻辑回归或线性核SVM
注意: SVM对特征缩放敏感,所以必须要对特征进行归一化或标准化处理。因为SVM是一种跟距离计算有关的模型,如果不进行特征缩放,那么具有较大范围值的特征对距离的影响会比其他特征更大,另外核函数往往涉及向量内积的计算,特征缩放可以有效避免数值问题(溢出)