

Batch Normalization(简称 BN)是指对上一层的输出或者激活层的输入做标准化处理,从而使得激活层的输入值的分布更合适,进而加快收敛速度。

上图表示一个多层神经网络在采用 BN 层和不采用 BN 层时不同层的对应输出分布,可见不使用 BN 层的输出大部分分布在两端,而使用 BN 层的输出分布则比较均衡。
什么是 Batch Normalization
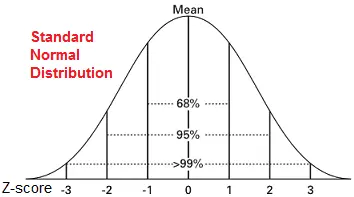
Batch Normalization 是指将线性激活函数的输入值变换为标准正态分布(均值为0,方差为1),使得其分布在激活函数的敏感区,从而加快收敛。如果不这么做,一旦激活函数的输入值分布在激活函数的极限饱和区,那么激活函数的梯度就会接近消失,从而无法更新参数或者参数更新很慢,进而影响模型的学习。
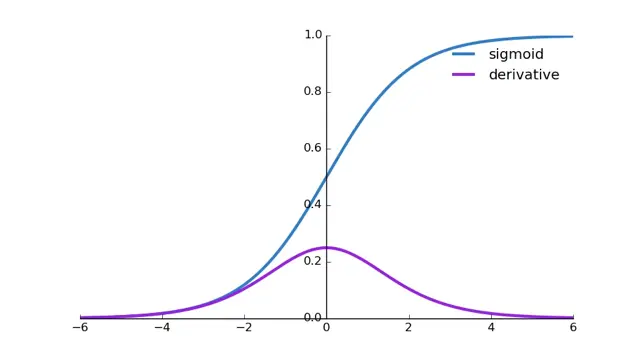
例如:sigmoid 函数,敏感区在[-2,2],两端的梯度逐渐消失,如果将输入变换为正态分布,那么95%的落点都在敏感区,有效避免梯度消失问题。
一味将输入值通过正态变换使得其落在敏感区也有问题,因为敏感区往往是偏线性的,这样会影响模型的表达能力,相当于失去了激活函数的意义(激活函数通过让模型损失一些输入信息从而达到非线性效果,例如 sigmoid 的两端),因此 BN 层还会通过 scale(γ斜率,即缩放,可以看成对方差的调整)和 shift(β截距,即移位, 可以看成对均值的调整)的操作使得落点分布在线性与非线性上获得平衡。
Relu 激活函数是否适合前接一个BN?
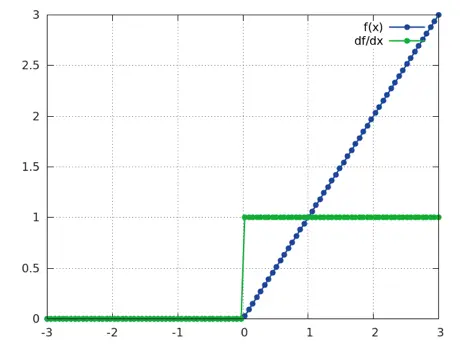
适合。通过 Batch Normalization 后,输入95%分布在(-2,2)大概有一半的输入得到激活,且保留非线性。
如何计算 Batch Normalization 的输出值
首先进行正态变换:

其中 E(x) 表示一个 batch 的均值,var(x) 表示一个 batch 的方差。(计算全局均值、方差需要非常大的计算开销,计算 batch 则非常高效,也许这就是为什么叫 Batch Normalization 的原因)
再通过 scale 和 shift 计算最终输出:
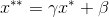
其中 γ 和 β 是要学习的参数。
举例:对于一个 batch_size 为 N, 宽为 P, 高为 Q 的特征图,一个 batch 的均值和方差就是基于这 N x P x Q 个特征计算所得,一个特征图学习一组 γ 和 β。
Batch Normalization 的优点
1.收敛更快,减少了训练时间(因为降低了梯度爆炸/消失的风险)。
2.减少了对正则化(dropout、L2)的需求,因为BN标准化是基于 batch 来计算均值和方差的,所以每个标准化产生的值都取决于当前的 batch,这本身就是一种正则化的体现。
3.允许设置更高的学习率(因为降低了梯度爆炸/消失的风险)。
Batch Normalization 的使用需要注意什么
1.由于均值和方差是针对 batch 计算的,所以如果 batch 太少,引入 BN 可能会有副作用。
2.对于不平衡的数据集,引入 BN 可能会导致更差的 Performance,因为对于不平衡语料,BN 不但没有做到“标准化”反而让不平衡的问题更加突出。