

YARN又称为Mapreduce version 2(MRv2)是hadoop2.x的新架构,它将旧Hadoop Mapreduce框架中的JobTracker的资源管理和作业生命周期管理拆分成两个组件即ResourceManager(RM)和ApplicationMaster(AM)
一、为何需要MRv2?
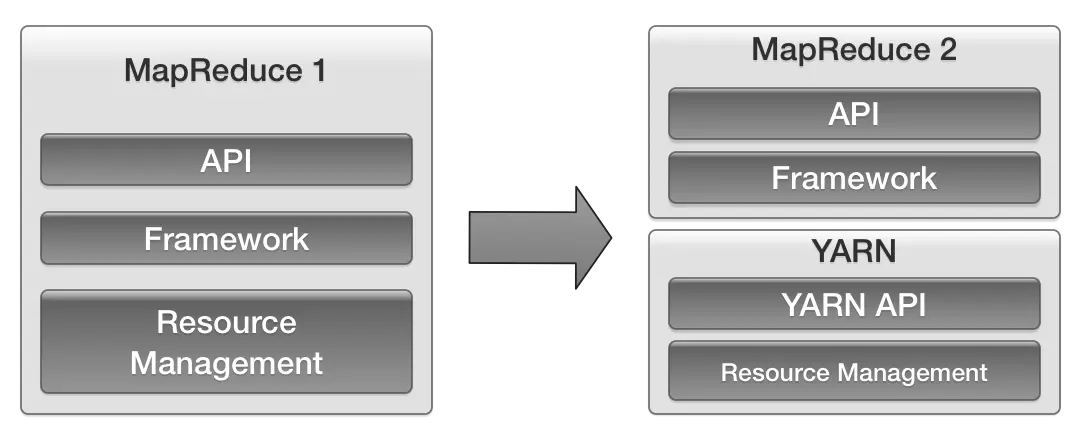
MRv1与MRv2对比
MRv1资源管理问题
- Hadoop1.0引入了“slot”的概念,每个slot代表了各个节点上的一份资源(CPU、内存等),MRv1把Map和Reduce的资源单独区分,即Map slot、Reduce slot,两个阶段的slot不能共享,这意味着资源的利用率大大降低
- 非MR应用不能分享资源,所以只能运行MR计算框架的应用
- 每个集群只有一个JobTracker,限制了集群的扩展,集群规模限制在4000个节点左右
MRv2资源管理方案
- 舍弃“slot”的概念,每个节点以“资源”(CPU、内存等)为单位分配给有需要的应用
- 支持运行MR应用和非MR应用
- JobTracker的大量功能被迁移到ApplicationMaster(AM),集群内可以存在多个AM(每个应用程序都拥有一个独立的AM),集群可以扩展到上万个节点
二、YARN架构
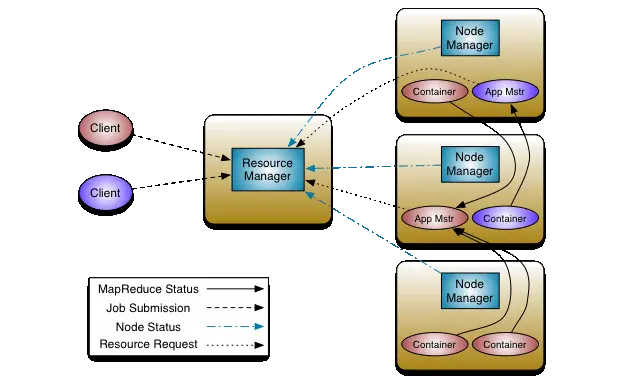
YARN架构图(via Apache Hadoop)
资源管理器(ResourceManager,RM)
ResourceManager运行在主节点(Master)上,负责全局资源调度(分配/回收),处理各个应用的资源请求,ResourceManager由调度器(Scheduler)和应用管理器(ApplicationsManager, AsM)组成
- 调度器(Scheduler)
调度器根据资源调度策略(例如Capacity Scheduler、Fair Scheduler),将包含适当资源(CPU、内存等)的资源容器(Container)分配给相应的节点,应用程序的各个任务均在容器内执行,且只能使用容器分配到的资源.调度器只负责资源调度,不关心应用的执行状态.
阅读全文