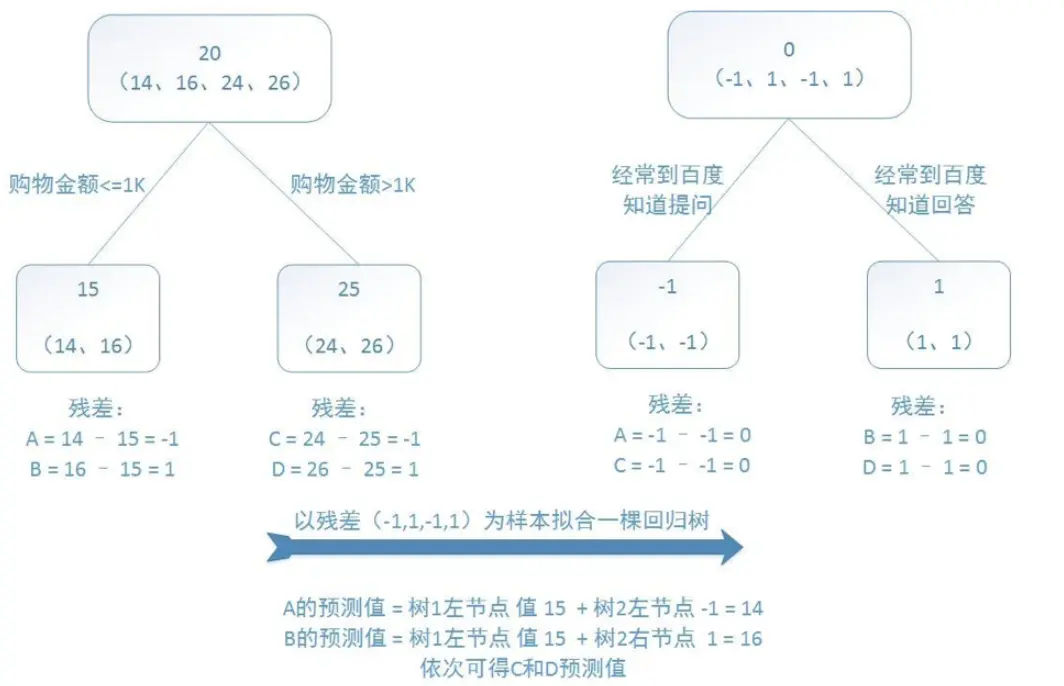
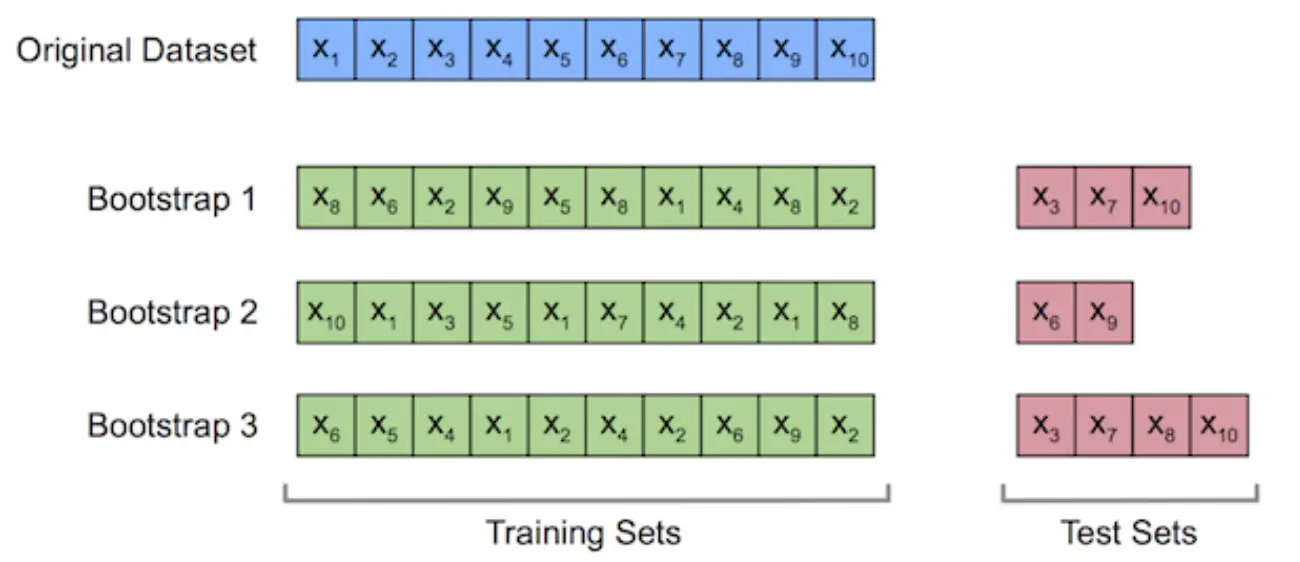
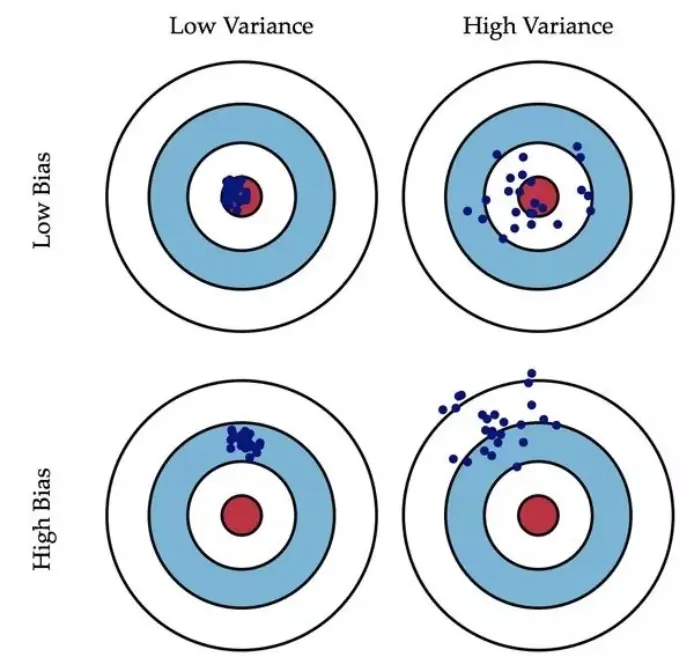
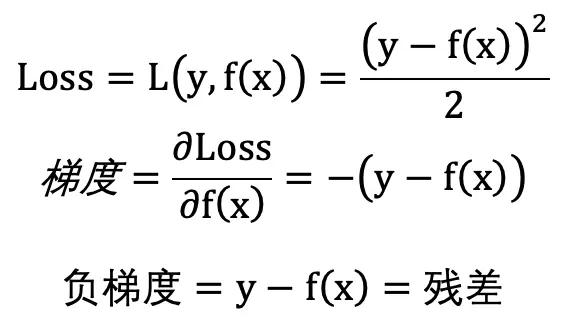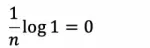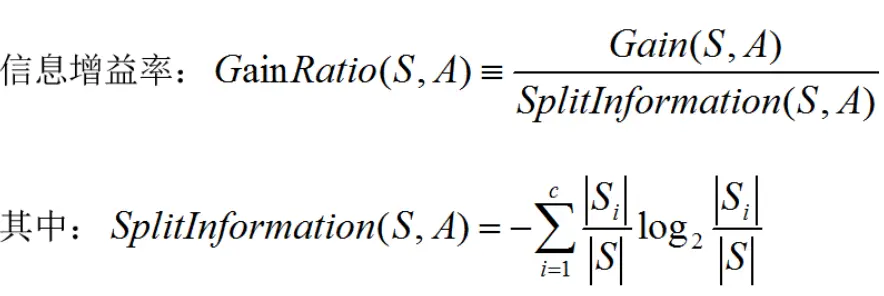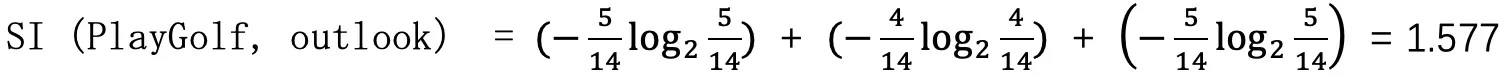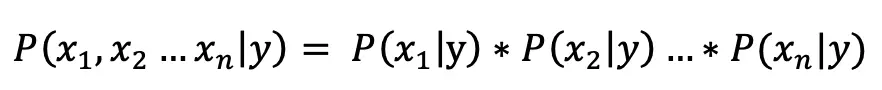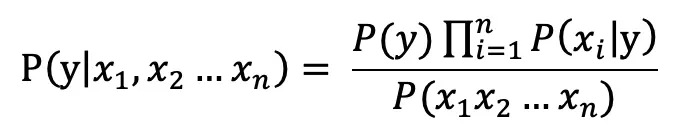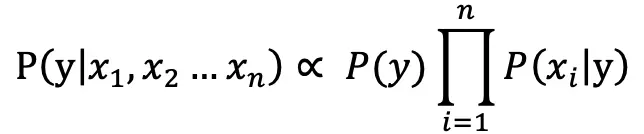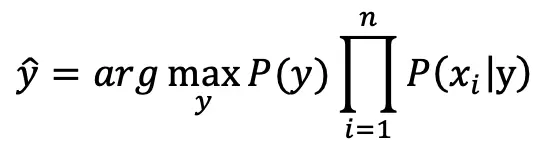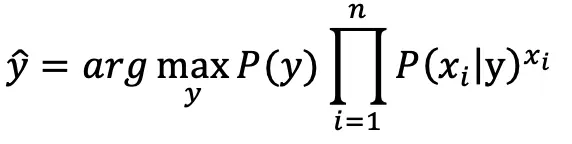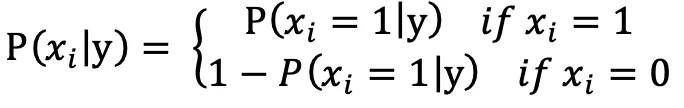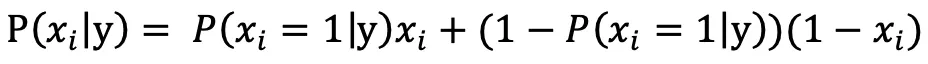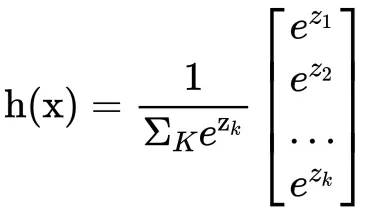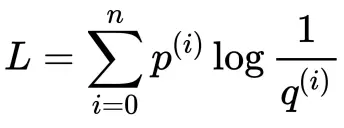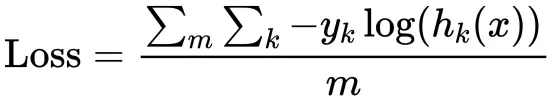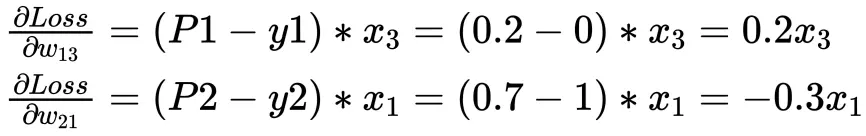对文本提取关键词,除了经典的 TF-IDF 算法,还有另一种常用的算法 — TextRank
TextRank 介绍
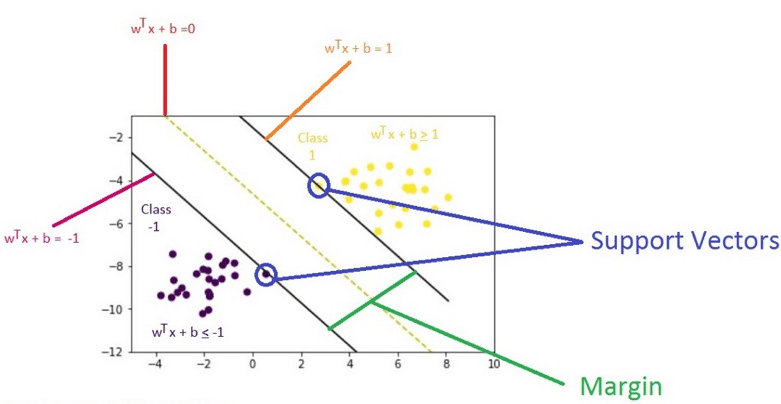
TextRank 是一种基于图的排序算法,它的基本思想来自于著名的 Google PageRank.

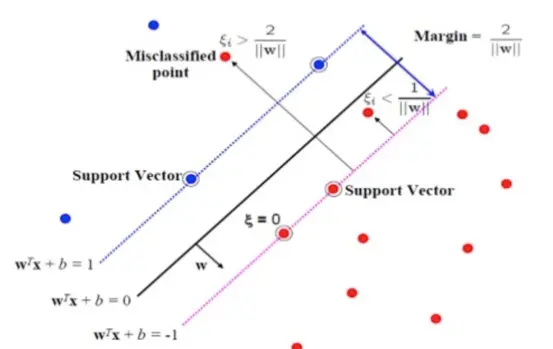
图:PageRank via @Wikipedia
PageRank 的基本思想
- 一个网页的入链越多,它就越重要。
- 如果一个网页被越重要的网页所指向,它也越重要。
TextRank 算法简释
下图是通过 TextRank 进行关键词提取的一个简单例子
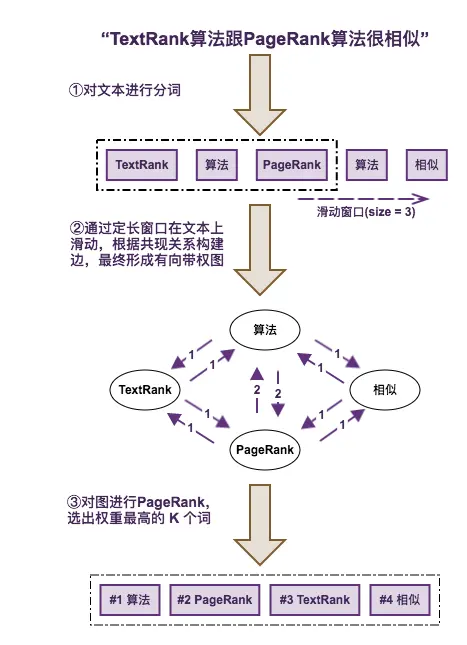
图:通过 TextRank 提取文本关键词
通过 TextRank 进行关键词提取的主要步骤
- 对文本进行分词,并去掉停用词以及非目标词性词汇。
- 通过一个固定长度的滑动窗口在分词文本上滑动,每个窗口内的词根据共现关系构建一条边,最终形成一个图。
- 对图进行 PageRank,实际上就是投票和迭代的过程。
- 选出权重最高的 TopK 个词。
算法总结
- TextRank 算法一定程度上考虑了文本中词与词之间的关系,也就是文本结构,在实际应用中它的效果一般会比 TF-IDF 好,当然它的计算复杂度也比 TF-IDF 高得多。
- TextRank 算法更擅长处理长文本,对短文本的效果并不理想,主要因为短文本的词汇信息较弱,构建的图并不理想。
- TextRank 算法仍然倾向于选择出现较为频繁的词作为关键词。