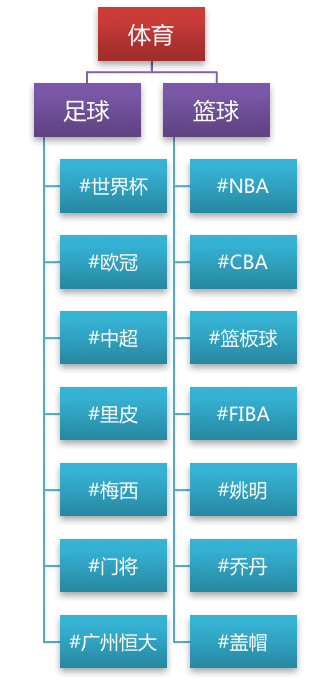
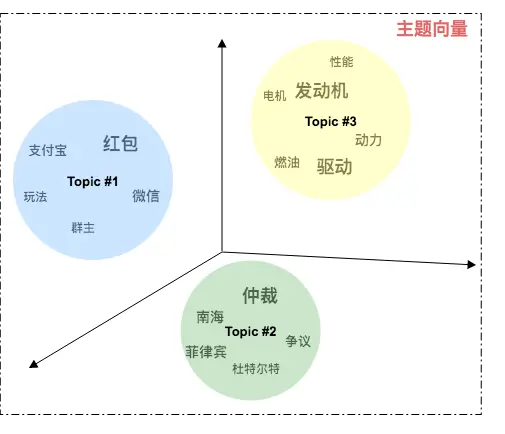
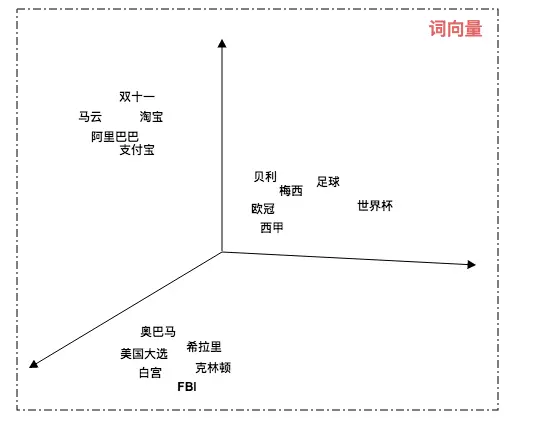
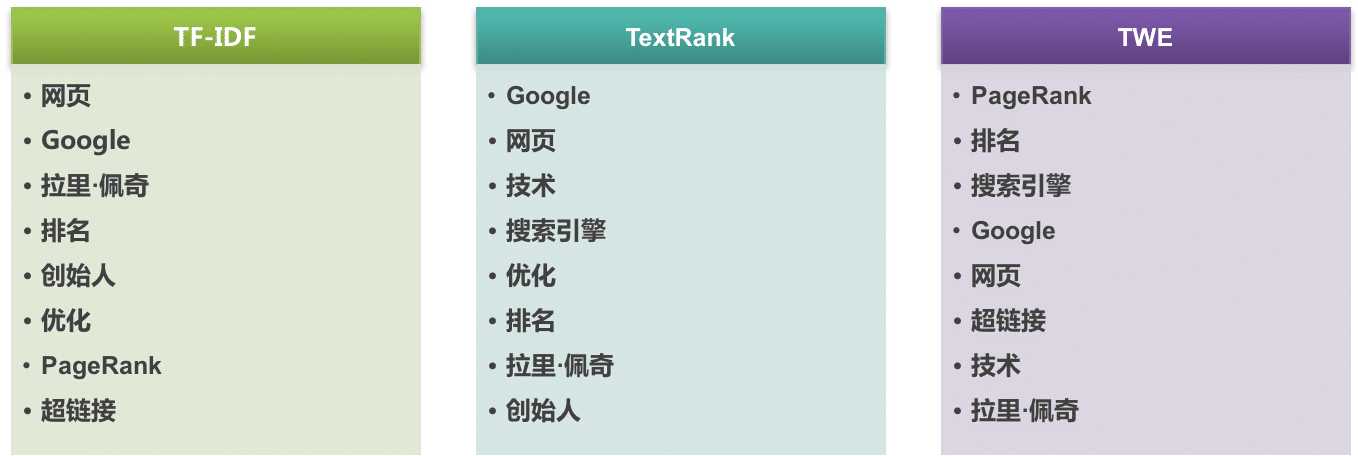
在大多数 UGC、PGC、OGC 平台中,“推荐”随处可见,本文主要介绍个性化推荐系统的抽象组成。
关于推荐
人工 VS 个性化
- 早期的推荐功能大多以人工筛选为主。人工筛选可以确保内容的高质量,这是主要的优点之一,但人工筛选往往需要投入大量的人力成本。另外,由于不同用户的个人偏好差异巨大,高质量的内容往往不等于最合适的内容(例如:一篇介绍奢侈品牌化妆品的“高大上”内容对于一位平时只关心美食和户外运动的用户而言可能是毫无吸引力的)。
- 为了提升用户体验,后来出现了“个性化内容推荐”的概念,通过引入个性化推荐系统,解决这类“千人千面”的问题。
推荐系统抽象
个性化推荐系统一般有三大环节:预处理 -> 召回 -> 排序 。
注:也可以认为是两层(召回 -> 排序)
预处理
第一个环节是预处理,预处理指的是对各种数据源的数据进行特征提取和特征构建,例如:内容特征提取,用户行为画像构建。
召回
第二个环节是召回,召回就是把预处理产生的特征作为输入参数,训练出推荐模型,然后使用推荐模型得出候选集合的过程。常用的召回方式有:基于内容推荐、基于协同过滤推荐等。
排序
第三个环节是排序,简单来说就是将候选集合根据一定的规则,例如:点击预估、匹配关联度、人为权重等进行调整,从而影响最后的推荐顺序。
推荐系统架构
最后简单画了一个基本的推荐系统架构原型
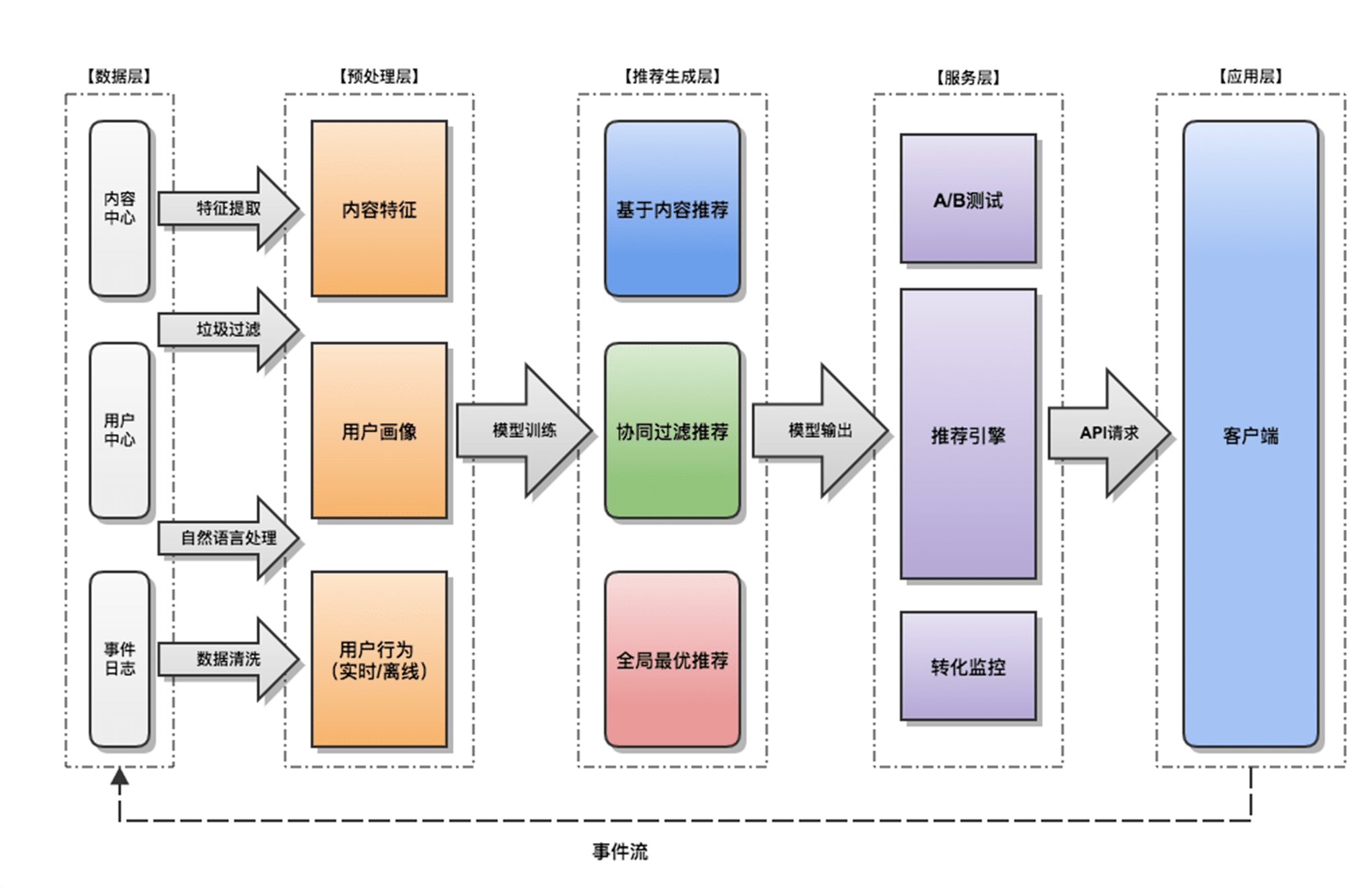
图:个性化推荐系统架构 ©️hejunhao.me