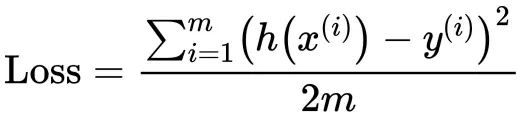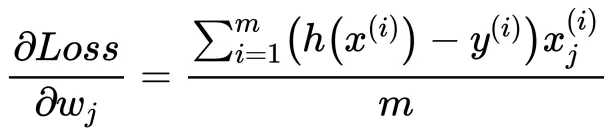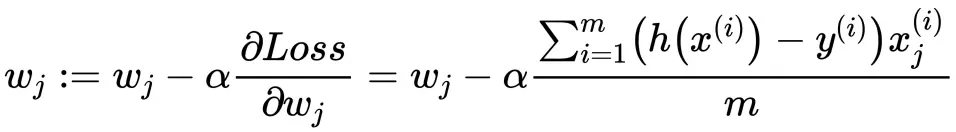简单介绍 方差、标准差、均方误差、协方差的基本概念以及计算公式,以区分它们的作用。
方差(Variance)
用来度量随机变量和其数学期望(即均值)之间的偏离程度
σ^2 = \dfrac{(x_1 - \bar{X})^2 + (x_2 - \bar{X})^2 ... + (x_n - \bar{X})^2}{(n-1)} = \dfrac{\sum_{i=1}^n{(x_i - \bar{X})^2}}{(n-1)}
备注:n-1 原因是无偏估计
标准差(Standard Deviation)
又叫均方差 , 反映一个数据集的离散程度(波动大小).
标准差 = 方差的算术平方根
σ = \sqrt{\dfrac{(x_1 - \bar{X})^2 + (x_2 - \bar{X})^2 ... + (x_n - \bar{X})^2}{(n-1)}} =\sqrt{\dfrac{\sum_{i=1}^n{(x_i - \bar{X})^2}}{(n-1)}}
问:有了方差为何需要标准差?
答:标准差的量纲(单位)与数据集一致,更直观描述波动范围。
均方误差(Mean Squared Error)
用来度量预测值与真实值的偏离程度
y:预测值 , Y:真实值
MSE = \dfrac{(y_1 - Y_1)^2 + (y_2 - Y_2)^2 ... + (y_n - Y_n)^2}{n} = \dfrac{\sum_{i=1}^n{(y_i - Y_i)^2}}{n}
协方差 (Covariance)
两个变量有多大的“可能”朝一个方向改变?协方差用于度量这个“可能”的程度。�如果两个变量的变化方向一致,那么协方差为正,反之为负。其中,变化指变量与它的数学期望的差值。
Cov(x,y) = \dfrac{(x_1 - \bar{X})(y_1 - \bar{Y}) + (x_2 - \bar{X})(y_2 - \bar{Y}) ... + (x_n - \bar{X})(y_n - \bar{Y})}{(n-1)}
= \dfrac{\sum_{i=1}^n{(x_i - \bar{X})(y_i - \bar{Y})}}{(n-1)}
当 cov(x,y)>0 ,则 X 与 Y 正相关;
当 cov(x,y)<0 , 则 X 与 Y 负相关;
当 cov(x,y)=0 ,则 X 与 Y 不相关。
转载请注明出处:
© http://hejunhao.me