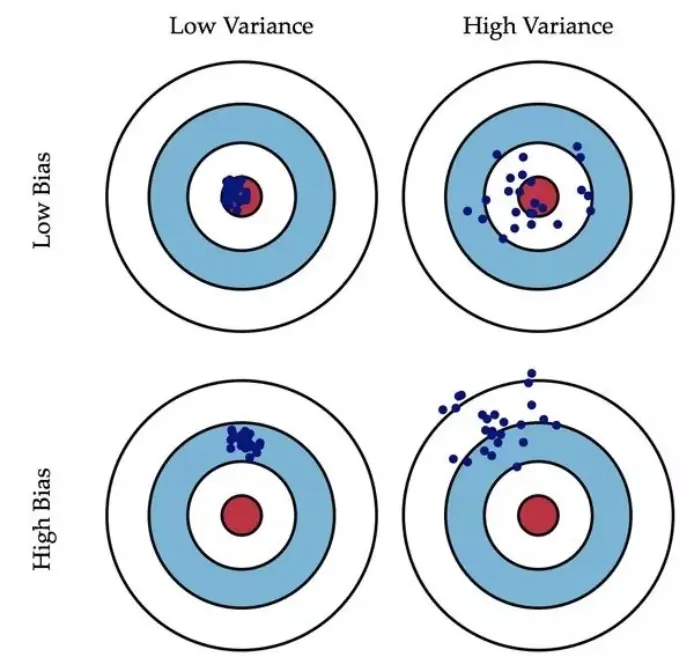
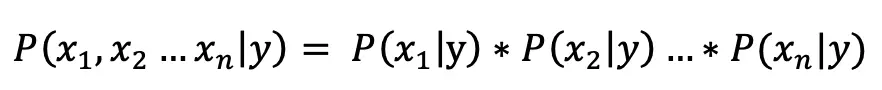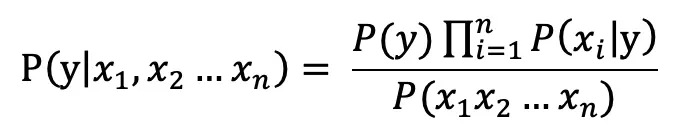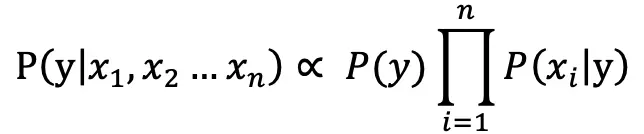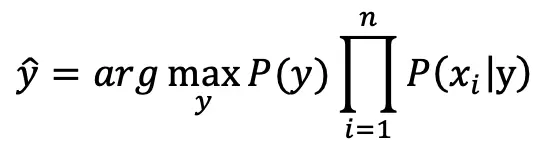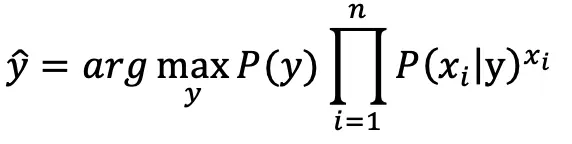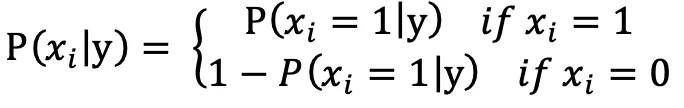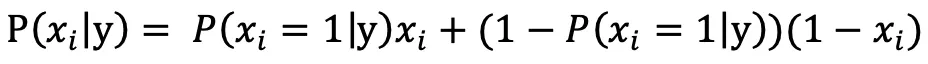在之前的两篇文章中分别介绍了两种常见的关键词提取算法:TF-IDF 和 TextRank。实际上不管是 TF-IDF 还是 TextRank,它们都没有考虑文本的语义,也就是文本的内容意义。为了进一步提升效果,我们引入主题模型(LDA)和词向量模型(word2vec)也就是TWE算法。
TWE (Topical Word Embedding)
主题模型
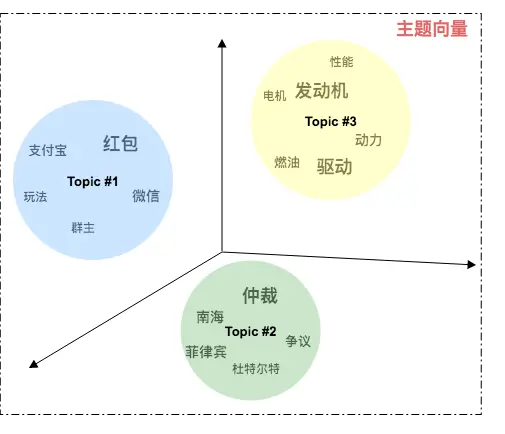
图:主题向量模型
- 在主题模型中每个主题实际上是一系列代表该主题的词的分布 ,例如:上图主题 Topic#1 包含的主题词分布主要有 “红包”、“微信”、“支付宝”、“玩法”等,文字大小代表该词的概率分布差异,可以推断 Topic#1 是一个关于新年红包活动的主题。
词向量模型
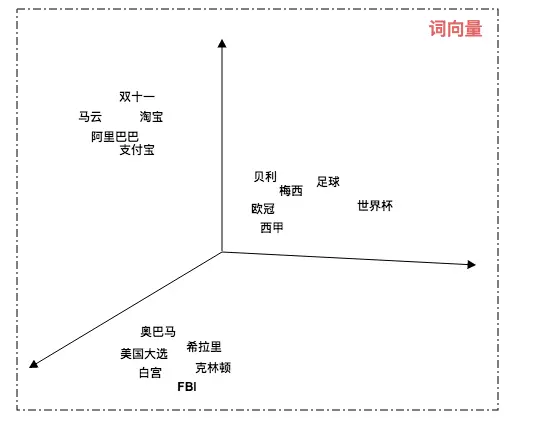
图:词向量模型
- 在词向量模型中每个词都有自己的坐标,关联度越高的词相互的距离越近。例如:“梅西” 和 “足球” 的距离比 “奥巴马” 与 “足球” 的距离要近得多,所以 “梅西” 与 “足球” 的关联度相比 “奥巴马” 更高。
基于 TWE 提取关键词
- 通过主题模型我们可以知道一段文本的主题分布:P(topic | doc)
- 结合词向量和主题向量,我们可以通过余弦函数计算两者的距离:cos(word_vec, topic_vec)
- 通过计算词向量与该文本所有关联主题的主题向量的余弦相似度,最终得到词与文本的语义关联度:
Sim\displaystyle\text{(word, doc)}=\sum_{k=1}^K \cos(\text{word\_vec, topic\_vec}_{_k}) \times P(\text{topic}_{_k} \mid \text{doc})
算法比较
假设有以下一段文本:

分别对该文本采用 TF-IDF、TextRank 以及 TWE 算法提取关键词,结果如下:
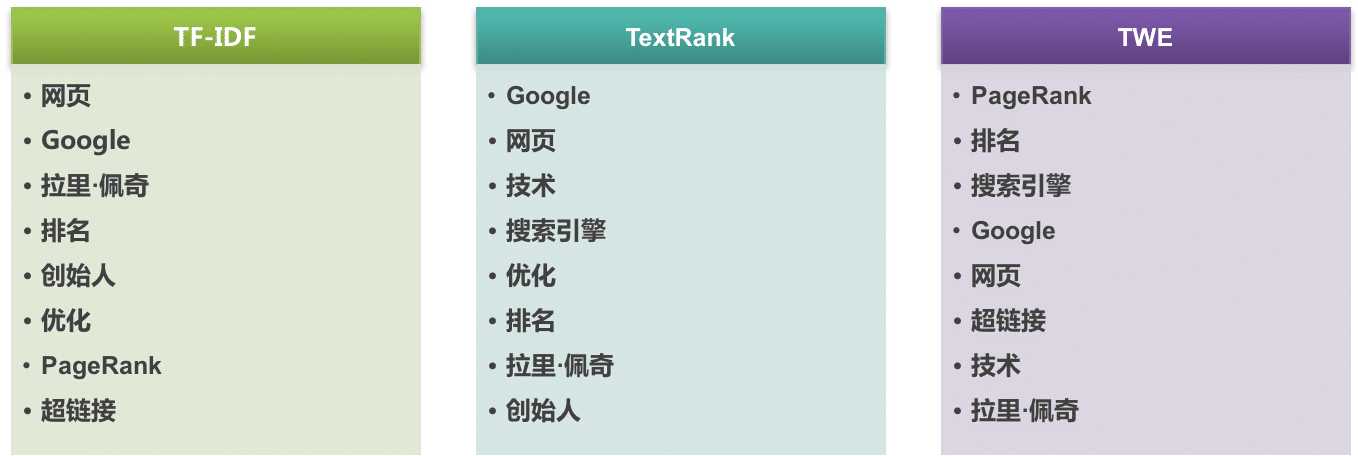
效果评价
- TF-IDF 更倾向于高频词。
- TextRank 综合考虑文本结构和词频,但它致命的问题在于,头尾的信息由于只有单边的入度,容易被抛弃掉,例如本例中的核心词 “pagerank”。
- TWE 更强调语义相关性,实际的提取效果也优于前面两种方式。
论文参考
- Yang Liu, Zhiyuan Liu, Tat-Seng Chua, Maosong Sun. 2015 Topical Word Embeddings
- Di Jiang, Zeyu Chen, Rongzhong Lian, Siqi Bao and Chen Li. 2017. Familia: An Open-Source Toolkit for Industrial Topic Modeling. arXiv preprint arXiv:1707.09823.